Appearance
🗄️ Thema 4: Datenbanken
Überblick
In diesem Themenbereich geht es darum, wie größere Datenmengen sinnvoll gespeichert, strukturiert, abgefragt, verändert und kritisch ausgewertet werden können.
Datenbanken begegnen uns ständig:
- in Schulverwaltungsprogrammen,
- in Bibliotheken,
- bei Online-Shops,
- bei Streamingdiensten,
- in Apps mit Benutzerkonten,
- bei Buchungs- und Reservierungssystemen,
- in Krankenhäusern,
- bei Banken, Versicherungen und Behörden.
Eine Datenbank speichert Daten nicht einfach „irgendwo“. Sie ordnet Daten nach einer klaren Struktur. Dadurch können Informationen zuverlässig gesucht, miteinander verknüpft, ausgewertet und kontrolliert verändert werden.
Leitfrage
Wie lassen sich Daten so organisieren, dass sie eindeutig, widerspruchsarm, effizient und verantwortungsvoll genutzt werden können?
Daten, Datenbank, Datenbanksystem
Daten sind Zeichen, Werte oder Beschreibungen von Sachverhalten. Sie können Zahlen, Texte, Datumsangaben, Wahrheitswerte, Bilder oder andere gespeicherte Informationen sein.
Beispiele:
| Datenwert | mögliche Bedeutung |
|---|---|
17 | Alter, Klassennummer, Stückzahl oder Preis |
2026-05-12 | Geburtsdatum, Ausleihdatum oder Termin |
wien | Stadt, Suchbegriff oder Benutzername |
true | Zustimmung, Verfügbarkeit oder Status |
Erst durch den Kontext wird aus einem Datenwert sinnvolle Information. Die Zahl 17 allein sagt noch wenig aus. Als Wert im Attribut Alter ist sie anders zu deuten als im Attribut Zimmernummer.
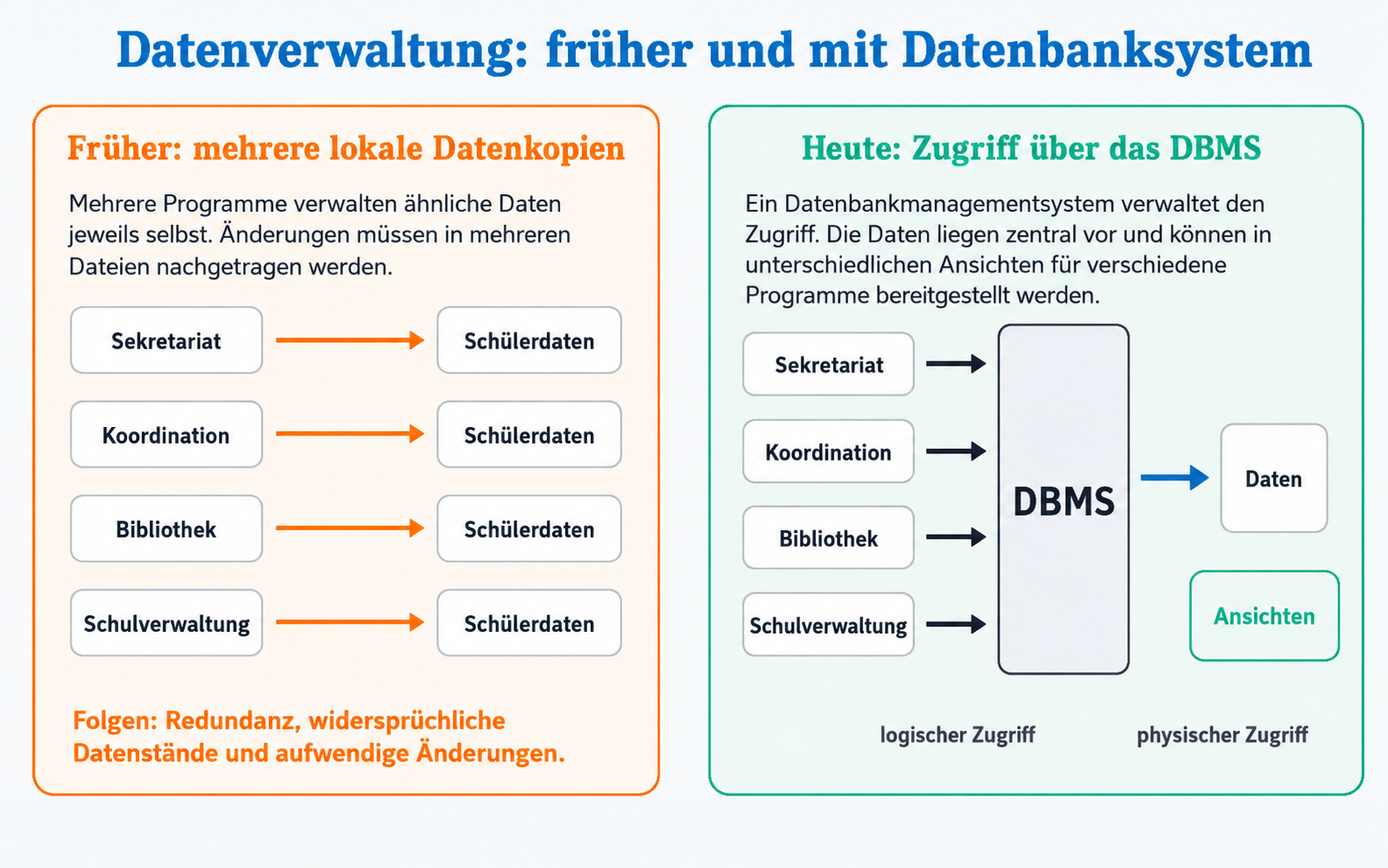
Eine Datenbank ist eine geordnete Sammlung zusammengehöriger Daten. Ein Datenbanksystem (DBS) umfasst zusätzlich die Software, mit der diese Daten verwaltet werden.
txt
Datenbanksystem = Datenbank + DatenbankmanagementsystemDas Datenbankmanagementsystem (DBMS) ist die Software, die Daten speichert, sucht, verändert, schützt und für verschiedene Programme bereitstellt.
Merke
Die Datenbank enthält die Daten. Das DBMS verwaltet den Zugriff auf diese Daten.
Warum Datenbanken?
Kleine Listen lassen sich gut in einer Tabellenkalkulation verwalten. Sobald Daten aber größer, vernetzter oder gemeinschaftlich genutzt werden, entstehen typische Probleme:
- dieselben Daten werden mehrfach gespeichert,
- verschiedene Personen arbeiten mit unterschiedlichen Versionen,
- Änderungen müssen an mehreren Stellen durchgeführt werden,
- mehrere Programme oder Nutzer·innen greifen gleichzeitig zu,
- Zugriffsrechte müssen beachtet werden,
- Datensätze sollen schnell gefiltert, sortiert und ausgewertet werden,
- Daten sollen langfristig widerspruchsfrei bleiben.
Tabellenkalkulation oder Datenbanksystem?
Tabellenkalkulationsprogramme und Datenbanksysteme können beide Daten tabellarisch darstellen. Sie haben aber unterschiedliche Stärken.
| Tabellenkalkulation | Datenbanksystem |
|---|---|
| gut für Berechnungen, kleinere Listen, Diagramme | gut für große, strukturierte und verknüpfte Datenbestände |
| oft als einzelne Datei gespeichert | häufig zentral auf einem Server gespeichert |
| sehr flexibel, aber leichter fehleranfällig | stärker geregelt und kontrollierbar |
| gut für Einzelpersonen oder kleine Gruppen | gut für viele gleichzeitige Nutzer·innen |
| Formeln, Zellbezüge und Auswertungen stehen im Vordergrund | Tabellen, Beziehungen, Schlüssel und Abfragen stehen im Vordergrund |
| Änderungen passieren direkt in Zellen | Änderungen laufen über definierte Strukturen und Rechte |
Wichtig
Eine Tabellenkalkulation ist nicht „schlechter“ als eine Datenbank. Beide Werkzeuge sind für unterschiedliche Aufgaben geeignet.
Wann reicht eine Tabellenkalkulation?
Eine Tabellenkalkulation ist sinnvoll, wenn Daten überschaubar sind und Berechnungen oder Diagramme im Vordergrund stehen.
Beispiele:
- private Ausgabenliste,
- Notenübersicht einer kleinen Lerngruppe,
- einfache Projektplanung,
- Diagramm zu Messwerten,
- einmalige Auswertung.
Wann ist ein Datenbanksystem sinnvoller?
Ein Datenbanksystem ist sinnvoll, wenn Daten dauerhaft, gemeinsam und strukturiert verwaltet werden müssen.
Beispiele:
- Schulverwaltung,
- Bibliothekssystem,
- Online-Shop,
- Vereinsverwaltung,
- Krankenhausinformationssystem,
- Benutzerverwaltung einer App.
Kurz gesagt
Tabellenkalkulationen sind stark bei Berechnungen. Datenbanken sind stark bei strukturierter, vernetzter und langfristiger Datenverwaltung.
Anforderungen an Datenbanksysteme
Ein gutes Datenbanksystem soll nicht nur Daten speichern. Es soll auch sicherstellen, dass Daten zuverlässig und kontrolliert genutzt werden können.
Wichtige Anforderungen sind:
| Anforderung | Bedeutung |
|---|---|
| Integritätssicherung | Daten sollen korrekt, vollständig und widerspruchsfrei bleiben. |
| Redundanzarmut | Dieselbe Information soll nicht unnötig mehrfach gespeichert werden. |
| Datensicherheit | Daten sollen vor Verlust, Manipulation und unberechtigtem Zugriff geschützt werden. |
| Datenschutz | Personenbezogene Daten dürfen nur rechtmäßig und zweckgebunden verarbeitet werden. |
| Mehrbenutzerbetrieb | Mehrere Personen oder Programme können gleichzeitig arbeiten. |
| Datenunabhängigkeit | Programme sollen möglichst unabhängig von der internen Speicherung bleiben. |
| zentrale Kontrolle | Verwaltung, Rechte und Sicherung können zentral organisiert werden. |
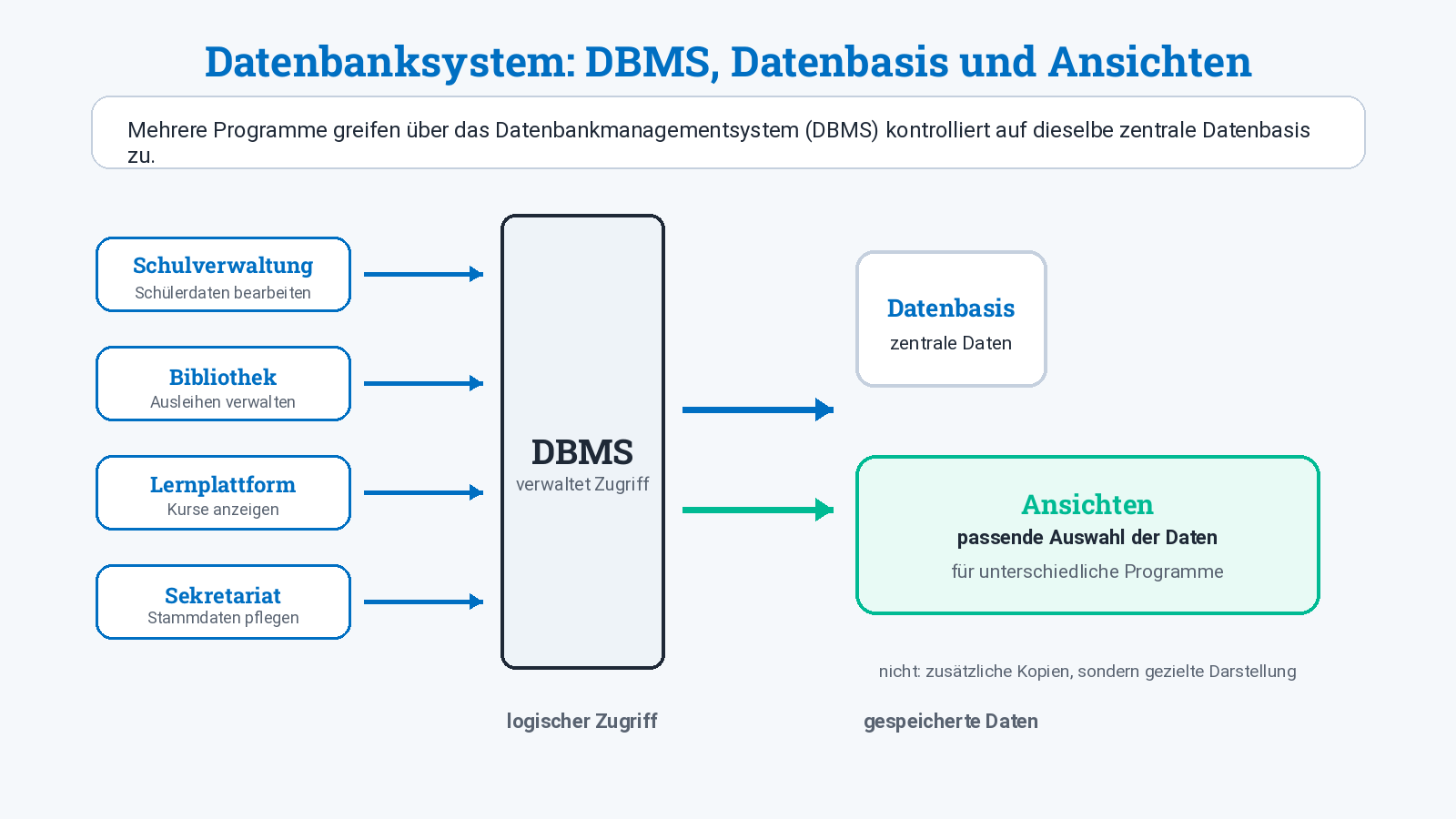
Ansichten statt vollständiger Datenzugriff
Ein DBMS kann Daten je nach Aufgabe in unterschiedlichen Ansichten bereitstellen.
Eine Ansicht bedeutet: Ein Programm oder eine Person sieht nicht automatisch alle gespeicherten Daten, sondern nur jene Ausschnitte, die für die jeweilige Aufgabe sinnvoll und erlaubt sind.
Beispiele:
- Die Bibliothek sieht Ausleihdaten und Namen, aber keine medizinischen Informationen.
- Eine Lehrperson sieht nur Daten der eigenen Kurse.
- Ein Statistikmodul sieht zusammengefasste Zahlen, aber keine vollständigen personenbezogenen Details.
- Ein Sekretariat kann Stammdaten bearbeiten, ein Schüler·innenportal zeigt nur ausgewählte Informationen an.
Merksatz
Ansichten sind passende Ausschnitte aus einer Datenbasis. Sie helfen, Daten übersichtlich bereitzustellen und Zugriffe einzuschränken.
Relationale Datenbanken
Besonders verbreitet sind relationale Datenbanksysteme. Dabei werden Daten in Tabellen gespeichert.
Eine Tabelle beschreibt eine bestimmte Art von Dingen, Personen, Vorgängen oder Objekten.
Beispiele:
txt
Schueler
Kurs
Buch
Ausleihe
Kunde
Bestellung
ProduktEine relationale Datenbank besteht meist aus mehreren Tabellen, die über Schlüssel miteinander verbunden sind.
Zentrale Begriffe
| Begriff | Bedeutung |
|---|---|
| Tabelle / Relation | Sammlung gleichartiger Datensätze |
| Attribut / Spalte | Eigenschaft eines Datensatzes |
| Attributwert | konkreter Wert in einer Zelle |
| Datensatz / Tupel / Zeile | ein konkreter Eintrag in einer Tabelle |
| Relationenschema | Kurzbeschreibung einer Tabelle mit ihren Attributen |
| Primärschlüssel | Attribut oder Attributkombination zur eindeutigen Identifikation |
| Fremdschlüssel | Attribut, das auf einen Primärschlüssel einer anderen Tabelle verweist |

Relationenschema
Ein Relationenschema beschreibt eine Tabelle kompakt. In dieser Lernunterlage wird dabei folgende Schreibweise verwendet:
- Primärschlüssel werden unterstrichen.
- Fremdschlüssel werden mit einem Pfeil nach oben und kursiv markiert: ↑ Fremdschlüssel.
- Der Pfeil bedeutet: Dieses Attribut verweist auf den Primärschlüssel einer anderen Tabelle.
Beispiel:
Person(PNr, Name, Vorname, PLZ, Ort)
Dabei ist PNr ein möglicher Primärschlüssel.
Wenn eine Tabelle auf eine andere Tabelle verweist, wird der Fremdschlüssel so notiert:
Klasse(KlasseID, Klassenname, Raum)
Schueler(SchuelerID, Vorname, Nachname, ↑ KlasseID)
Hier ist ↑ KlasseID in der Tabelle Schueler ein Fremdschlüssel. Er verweist auf den Primärschlüssel KlasseID der Tabelle Klasse.
Merke
Im Relationenschema erkennt man dadurch sofort:
- Was identifiziert einen Datensatz eindeutig?
- Welche Tabelle verweist auf eine andere Tabelle?
- Wo wurde eine Beziehung im relationalen Modell umgesetzt?
Mit Datentypen könnte man das Schema noch genauer notieren:
Person(PNr: INTEGER, Name: TEXT, Vorname: TEXT, PLZ: TEXT, Ort: TEXT)
Typische Datentypen sind:
| Datentyp | Bedeutung | Beispiel |
|---|---|---|
INTEGER | ganze Zahl | 17 |
TEXT / VARCHAR | Text | Wien |
BOOLEAN | Wahrheitswert | true / false |
DATE | Datum | 2026-05-12 |
DATETIME | Datum und Uhrzeit | 2026-05-12 08:30 |
FLOAT / DOUBLE | Kommazahl | 19.95 |
Merksatz
Ein Primärschlüssel identifiziert einen Datensatz eindeutig. Ein Fremdschlüssel verbindet Tabellen miteinander.
Schlüssel in relationalen Datenbanken
Namen sind selten eindeutig. Es kann mehrere Personen mit demselben Namen geben. Deshalb verwendet man in Datenbanken häufig künstliche IDs.
Beispiel:
Klasse(KlasseID, Klassenname)
Schueler(SchuelerID, Vorname, Nachname, ↑ KlasseID)
SchuelerID identifiziert Schüler·innen eindeutig. ↑ KlasseID verweist in der Tabelle Schueler auf einen Eintrag in der Tabelle Klasse.
Primärschlüssel
Ein Primärschlüssel muss jeden Datensatz eindeutig identifizieren.
Geeignet:
txt
SchuelerID
BuchID
Bestellnummer
MatrikelnummerProblematisch:
txt
Name
Vorname
Geburtsdatum allein
Adresse alleinDiese Werte können doppelt vorkommen oder sich ändern.
Fremdschlüssel
Ein Fremdschlüssel verweist auf einen Primärschlüssel einer anderen Tabelle.
Beispiel:
Klasse(KlasseID, Klassenname)
Schueler(SchuelerID, Vorname, Nachname, ↑ KlasseID)
↑ KlasseID in Schueler ist ein Fremdschlüssel. Dadurch wird gespeichert, zu welcher Klasse eine Schüler·in gehört.
Wichtig
Fremdschlüssel sorgen dafür, dass zusammengehörige Informationen nicht unkontrolliert mehrfach gespeichert werden müssen.
SQL
SQL steht für Structured Query Language. SQL ist eine Sprache, mit der relationale Datenbanken abgefragt und verändert werden können.
SQL kann unter anderem:
- Spalten auswählen,
- Zeilen filtern,
- Tabellen verknüpfen,
- Ergebnisse sortieren,
- Werte zählen oder berechnen,
- Daten einfügen, ändern oder löschen,
- Tabellenstrukturen beschreiben,
- Zugriffsrechte unterstützen.
In der Prüfungsvorbereitung steht vor allem das Lesen, Formulieren und Erklären von Abfragen im Vordergrund.
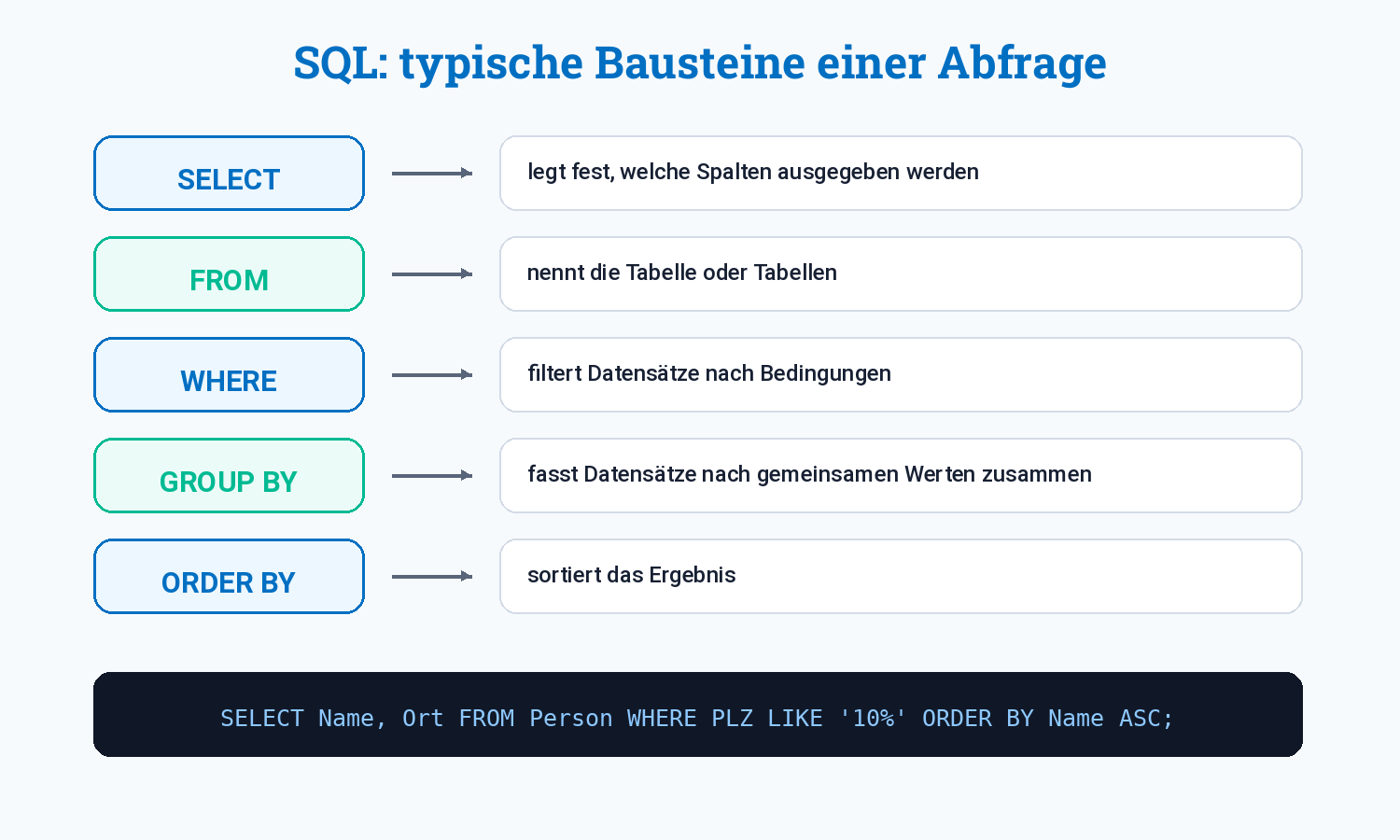
Grundstruktur einer SQL-Abfrage
sql
SELECT Attributliste
FROM Tabellenliste
WHERE Bedingung
GROUP BY Gruppierung
HAVING Gruppenbedingung
ORDER BY Sortierung
LIMIT Anzahl;Nicht alle Bestandteile müssen immer vorkommen.
| SQL-Teil | Bedeutung |
|---|---|
SELECT | Welche Spalten oder Berechnungen sollen angezeigt werden? |
FROM | Aus welcher Tabelle oder welchen Tabellen stammen die Daten? |
WHERE | Welche einzelnen Datensätze sollen ausgewählt werden? |
GROUP BY | Nach welchen Attributwerten sollen Datensätze gruppiert werden? |
HAVING | Welche Gruppen sollen nach der Gruppierung behalten werden? |
ORDER BY | Wie soll das Ergebnis sortiert werden? |
LIMIT | Wie viele Datensätze sollen höchstens angezeigt werden? |
Merke
WHERE filtert einzelne Zeilen vor der Gruppierung. HAVING filtert Gruppen nach der Gruppierung.
Projektion und Selektion
Zwei Grundideen sind besonders wichtig:
| Begriff | Bedeutung | SQL-Bezug |
|---|---|---|
| Projektion | Auswahl bestimmter Spalten | SELECT Name, Ort |
| Selektion | Auswahl bestimmter Zeilen | WHERE Ort = 'Wien' |
Beispiel:
sql
SELECT Name, Ort
FROM Person
WHERE PLZ LIKE '10%';Diese Abfrage zeigt nur die Spalten Name und Ort. Außerdem werden nur jene Datensätze ausgewählt, deren Ortscode mit 10 beginnt.
Bedingungen und Operatoren
Mit WHERE werden Bedingungen formuliert.
sql
SELECT Titel, Jahr
FROM Film
WHERE Jahr >= 2020;Wichtige Vergleichsoperatoren:
| Operator | Bedeutung |
|---|---|
= | gleich |
<> oder != | ungleich |
< | kleiner als |
> | größer als |
<= | kleiner oder gleich |
>= | größer oder gleich |
LIKE | Mustervergleich |
BETWEEN ... AND ... | Wertebereich |
IN (...) | Wert kommt in einer Liste vor |
IS NULL | kein Wert vorhanden |
Logische Verknüpfungen
Mehrere Bedingungen lassen sich kombinieren.
sql
SELECT Titel, Jahr
FROM Film
WHERE Genre = 'Dokumentation' AND Jahr >= 2020;| Operator | Bedeutung |
|---|---|
AND | beide Bedingungen müssen erfüllt sein |
OR | mindestens eine Bedingung muss erfüllt sein |
NOT | Bedingung wird verneint |
Wichtig
Bei gemischten Bedingungen können Klammern notwendig sein, damit klar ist, was zuerst ausgewertet wird.
Beispiel:
sql
SELECT Name, Stadt
FROM Mitglied
WHERE Stadt = 'Wien' AND (Alter < 18 OR Alter > 65);Sortieren mit ORDER BY
sql
SELECT Name, Preis
FROM Produkt
ORDER BY Preis DESC;ASC bedeutet aufsteigend, DESC bedeutet absteigend.
Doppelte Ergebnisse vermeiden
Mit DISTINCT werden doppelte Ergebniszeilen entfernt.
sql
SELECT DISTINCT Stadt
FROM Mitglied;Diese Abfrage zeigt jede Stadt nur einmal.
Aggregatfunktionen
Aggregatfunktionen werten mehrere Datensätze zusammen aus.
| Funktion | Bedeutung |
|---|---|
COUNT() | zählt Datensätze |
SUM() | bildet eine Summe |
AVG() | berechnet einen Durchschnitt |
MIN() | kleinster Wert |
MAX() | größter Wert |
Beispiele:
sql
SELECT COUNT(*)
FROM Buch;sql
SELECT AVG(Preis)
FROM Produkt;sql
SELECT MAX(Punkte)
FROM Ergebnis;AS: Ergebnisspalten umbenennen
Mit AS kann eine Ergebnisspalte verständlicher benannt werden.
sql
SELECT COUNT(*) AS Anzahl_Buecher
FROM Buch;Das ändert nicht die Tabelle selbst, sondern nur die Spaltenüberschrift im Ergebnis.
GROUP BY
Mit GROUP BY werden Datensätze nach gleichen Attributwerten zusammengefasst.
Beispiel:
sql
SELECT Kategorie, COUNT(*) AS Anzahl
FROM Buch
GROUP BY Kategorie;Diese Abfrage zählt, wie viele Bücher pro Kategorie vorhanden sind.
HAVING
HAVING filtert Gruppen nach der Gruppierung.
sql
SELECT Kategorie, COUNT(*) AS Anzahl
FROM Buch
GROUP BY Kategorie
HAVING COUNT(*) > 5;Diese Abfrage zeigt nur Kategorien, in denen mehr als fünf Bücher vorkommen.
Merke
WHERE prüft einzelne Datensätze. HAVING prüft zusammengefasste Gruppen.
Tabellen verknüpfen
Informationen liegen in relationalen Datenbanken oft auf mehrere Tabellen verteilt.
Beispiel:
Schueler(SchuelerID, Vorname, Nachname)
Kurs(KursID, Kursname)
belegt(↑ SchuelerID, ↑ KursID)
Die Tabelle belegt verbindet Schüler·innen mit Kursen.
Eine Abfrage mit klassischer Verknüpfung kann so aussehen:
sql
SELECT Schueler.Vorname, Schueler.Nachname, Kurs.Kursname
FROM Schueler, belegt, Kurs
WHERE Schueler.SchuelerID = belegt.SchuelerID
AND belegt.KursID = Kurs.KursID;Eine moderne Schreibweise mit JOIN ... ON wäre:
sql
SELECT Schueler.Vorname, Schueler.Nachname, Kurs.Kursname
FROM Schueler
JOIN belegt ON Schueler.SchuelerID = belegt.SchuelerID
JOIN Kurs ON belegt.KursID = Kurs.KursID;Beide Varianten verbinden passende Datensätze über Schlüssel.
Wichtig
Wenn Tabellen verknüpft werden, müssen die passenden Schlüssel korrekt verbunden werden. Sonst entstehen falsche Kombinationen.
📝 Übung: SQL-Grundlagen
Gegeben ist die Tabelle:
txt
Buch(BuchID, Titel, Autor, Jahr, Kategorie, Verfuegbar)Formuliere SQL-Abfragen:
- Zeige alle Bücher an.
- Zeige nur Titel und Autor an.
- Zeige alle Bücher der Kategorie
Fantasy. - Sortiere alle Bücher nach Erscheinungsjahr absteigend.
- Zeige alle verfügbaren Bücher, die nach 2020 erschienen sind.
Lösung
sql
SELECT *
FROM Buch;sql
SELECT Titel, Autor
FROM Buch;sql
SELECT *
FROM Buch
WHERE Kategorie = 'Fantasy';sql
SELECT Titel, Jahr
FROM Buch
ORDER BY Jahr DESC;sql
SELECT Titel, Jahr
FROM Buch
WHERE Verfuegbar = true AND Jahr > 2020;📝 Übung: Aggregation und Gruppierung
Gegeben ist die Tabelle:
txt
Ausleihe(AusleiheID, BuchID, PersonID, Monat)Formuliere SQL-Abfragen:
- Zähle alle Ausleihen.
- Zähle die Ausleihen pro Monat.
- Zeige nur jene Monate, in denen es mehr als 20 Ausleihen gab.
Lösung
sql
SELECT COUNT(*) AS Anzahl_Ausleihen
FROM Ausleihe;sql
SELECT Monat, COUNT(*) AS Anzahl_Ausleihen
FROM Ausleihe
GROUP BY Monat;sql
SELECT Monat, COUNT(*) AS Anzahl_Ausleihen
FROM Ausleihe
GROUP BY Monat
HAVING COUNT(*) > 20;📝 Übung: SQL-Abfrage erklären
Erkläre in eigenen Worten, was diese Abfrage macht:
sql
SELECT Stadt, COUNT(*) AS Anzahl
FROM Mitglied
WHERE Aktiv = true
GROUP BY Stadt
HAVING COUNT(*) >= 3
ORDER BY Anzahl DESC;Lösungshinweis
Die Abfrage betrachtet nur aktive Mitglieder. Danach gruppiert sie diese Mitglieder nach Stadt und zählt pro Stadt die Datensätze. Angezeigt werden nur Städte mit mindestens drei aktiven Mitgliedern. Das Ergebnis wird nach der Anzahl absteigend sortiert.
📝 Übung: Tabellen verknüpfen
Gegeben ist folgendes Schema:
txt
Person(PersonID, Vorname, Nachname)
AG(AGID, Bezeichnung)
nimmt_teil(PersonID, AGID)Formuliere eine Abfrage, die Vorname, Nachname und AG-Bezeichnung aller Teilnahmen anzeigt.
Lösung
sql
SELECT Person.Vorname, Person.Nachname, AG.Bezeichnung
FROM Person, nimmt_teil, AG
WHERE Person.PersonID = nimmt_teil.PersonID
AND nimmt_teil.AGID = AG.AGID;Oder mit JOIN:
sql
SELECT Person.Vorname, Person.Nachname, AG.Bezeichnung
FROM Person
JOIN nimmt_teil ON Person.PersonID = nimmt_teil.PersonID
JOIN AG ON nimmt_teil.AGID = AG.AGID;Datenbankentwicklung
Eine gute Datenbank entsteht nicht erst beim Programmieren. Zuerst muss geklärt werden, welche Daten vorkommen, welche Beziehungen bestehen und welche Anforderungen erfüllt werden müssen.
Typische Entwicklungsschritte:
- Anforderungsspezifikation: Was soll das System leisten?
- Konzeptioneller Entwurf: Welche Entitäten, Attribute und Beziehungen gibt es?
- Logischer Entwurf: Wie wird daraus ein relationales Modell mit Tabellen und Schlüsseln?
- Physischer Entwurf: Welche Datentypen, Speicherformen, Rechte und technischen Details werden festgelegt?
- Implementierung und Erprobung: Tabellen anlegen, testen, Grunddaten eingeben.
- Nutzung und Pflege: Daten eingeben, auswerten, sichern und weiterentwickeln.
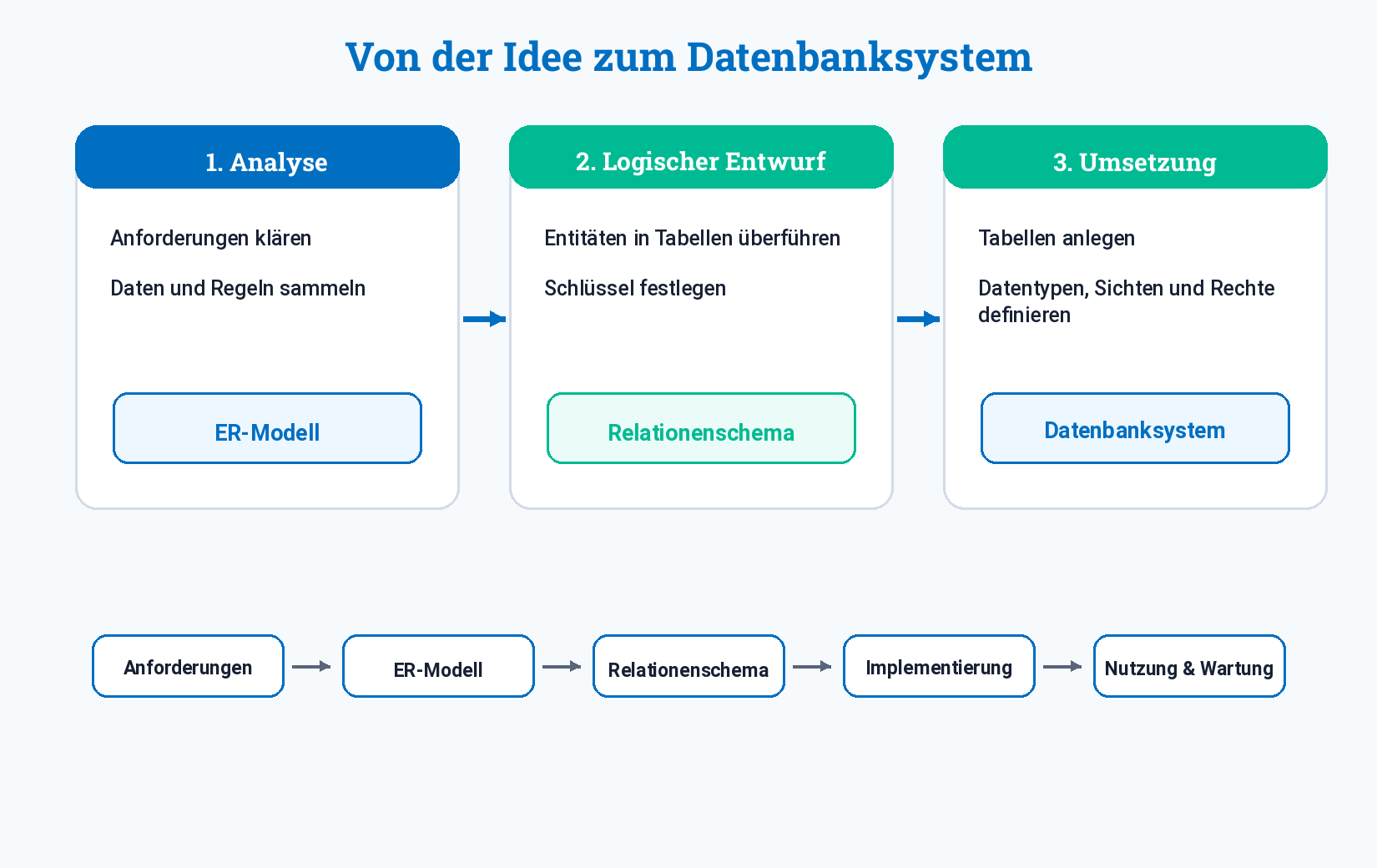
Merke
Je sauberer die Modellierung, desto weniger Probleme entstehen später bei Abfragen, Änderungen und Erweiterungen.
ER-Modell
Ein ER-Modell beschreibt Daten fachlich, bevor sie in konkrete Tabellen umgesetzt werden.
ER steht für:
- Entity: Entität,
- Relationship: Beziehung.
Entität, Entitätstyp und Entitätsmenge
Eine Entität ist ein eindeutig identifizierbares Objekt oder ein eindeutig beschreibbarer Vorgang.
Beispiele:
- eine konkrete Schüler·in,
- ein bestimmtes Buch,
- eine bestimmte Ausleihe,
- ein konkreter Kurs,
- eine konkrete Bestellung.
Ein Entitätstyp beschreibt gleichartige Entitäten.
Beispiele:
txt
Schueler
Buch
Ausleihe
Kurs
BestellungEine Entitätsmenge ist die Menge aller Entitäten eines Entitätstyps.
Attribut und Attributwert
Ein Attribut ist eine Eigenschaft eines Entitätstyps.
Beispiel:
txt
Schueler(Vorname, Nachname, Geburtsdatum)Ein Attributwert ist ein konkreter Wert eines Attributs.
txt
Vorname = "Mina"
Nachname = "Berger"
Geburtsdatum = "2008-04-12"Besondere Attribute
| Attributart | Bedeutung | Beispiel |
|---|---|---|
| Schlüsselattribut | identifiziert Entitäten eindeutig | SchuelerID |
| zusammengesetztes Attribut | besteht aus mehreren Teilinformationen | Adresse aus Straße, PLZ, Ort |
| mehrwertiges Attribut | kann mehrere Werte besitzen | mehrere Telefonnummern |
| abgeleitetes Attribut | kann aus anderen Werten berechnet werden | Alter aus Geburtsdatum |
Wichtig
Mehrwertige oder zusammengesetzte Informationen sollten im relationalen Modell besonders sorgfältig behandelt werden. Häufig werden sie in mehrere Attribute oder eigene Tabellen zerlegt.
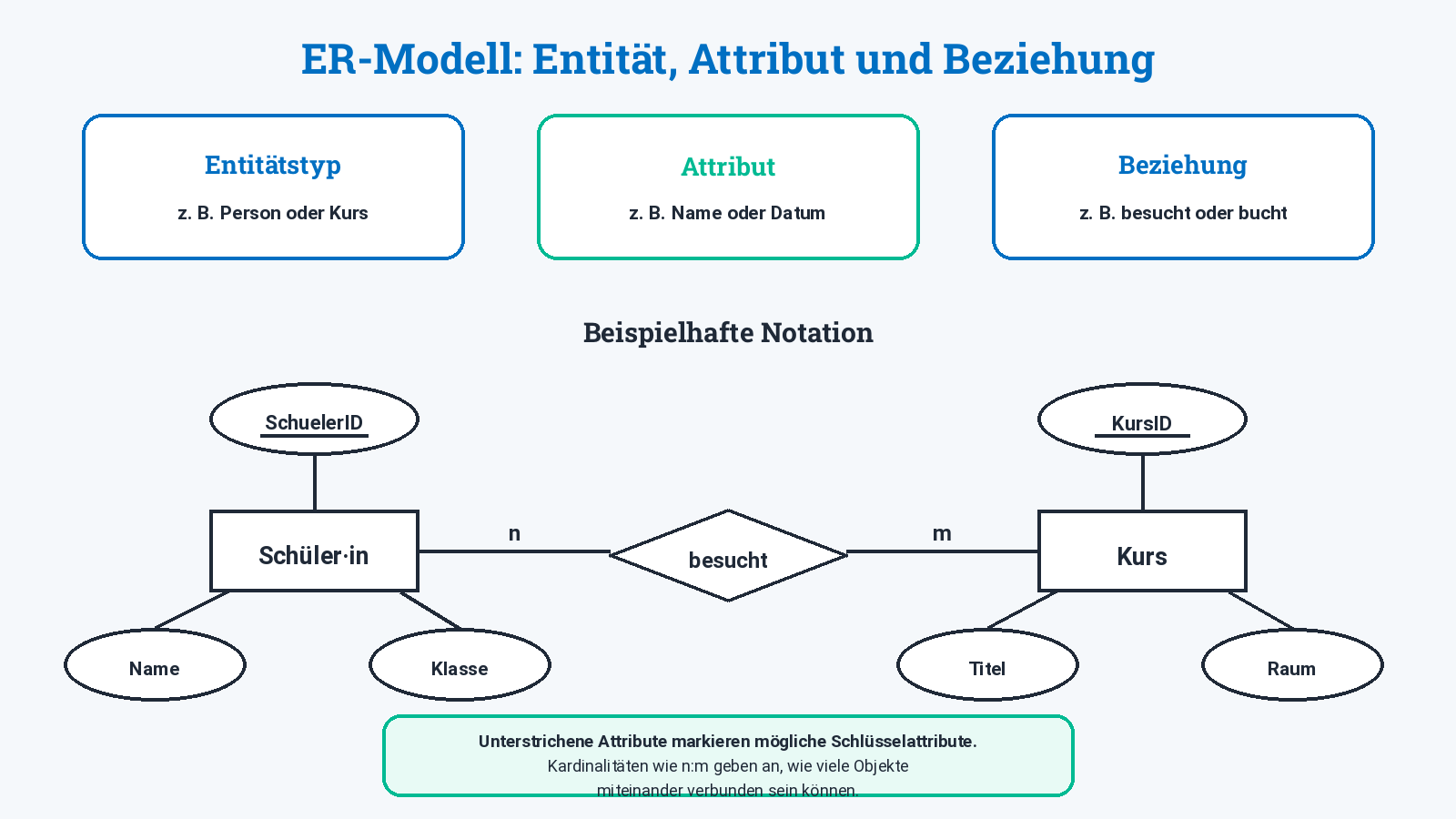
Beziehungen und Kardinalitäten
Eine Beziehung beschreibt, wie Entitäten miteinander zusammenhängen.
Beispiele:
txt
Schüler·in besucht Kurs
Person leiht Buch aus
Kunde bestellt Produkt
Lehrkraft betreut ProjektDer Name einer Beziehung sollte die inhaltliche Bedeutung möglichst klar ausdrücken. Häufig wird dafür ein Verb verwendet.
Beziehung in zwei Richtungen prüfen
Bei Beziehungen ist es hilfreich, beide Richtungen als Sätze zu formulieren.
Beispiel:
txt
Schüler·in geht_in KlasseRichtung 1:
Eine Schüler·in geht in höchstens eine Klasse.
Richtung 2:
Eine Klasse besteht aus mehreren Schüler·innen.
Daraus ergibt sich eine 1:n-Beziehung.
Kardinalitäten
Kardinalitäten geben an, wie viele Entitäten auf beiden Seiten einer Beziehung beteiligt sein können.
| Kardinalität | Bedeutung | Beispiel |
|---|---|---|
| 1:1 | Eine Entität ist höchstens einer anderen Entität zugeordnet. | Person - besitzt - Spind |
| 1:n | Eine Entität ist mehreren anderen zugeordnet; umgekehrt gehört jede nur zu einer. | Klasse - enthält - Schüler·innen |
| n:m | Mehrere Entitäten können mit mehreren anderen verbunden sein. | Schüler·innen - besuchen - Kurse |
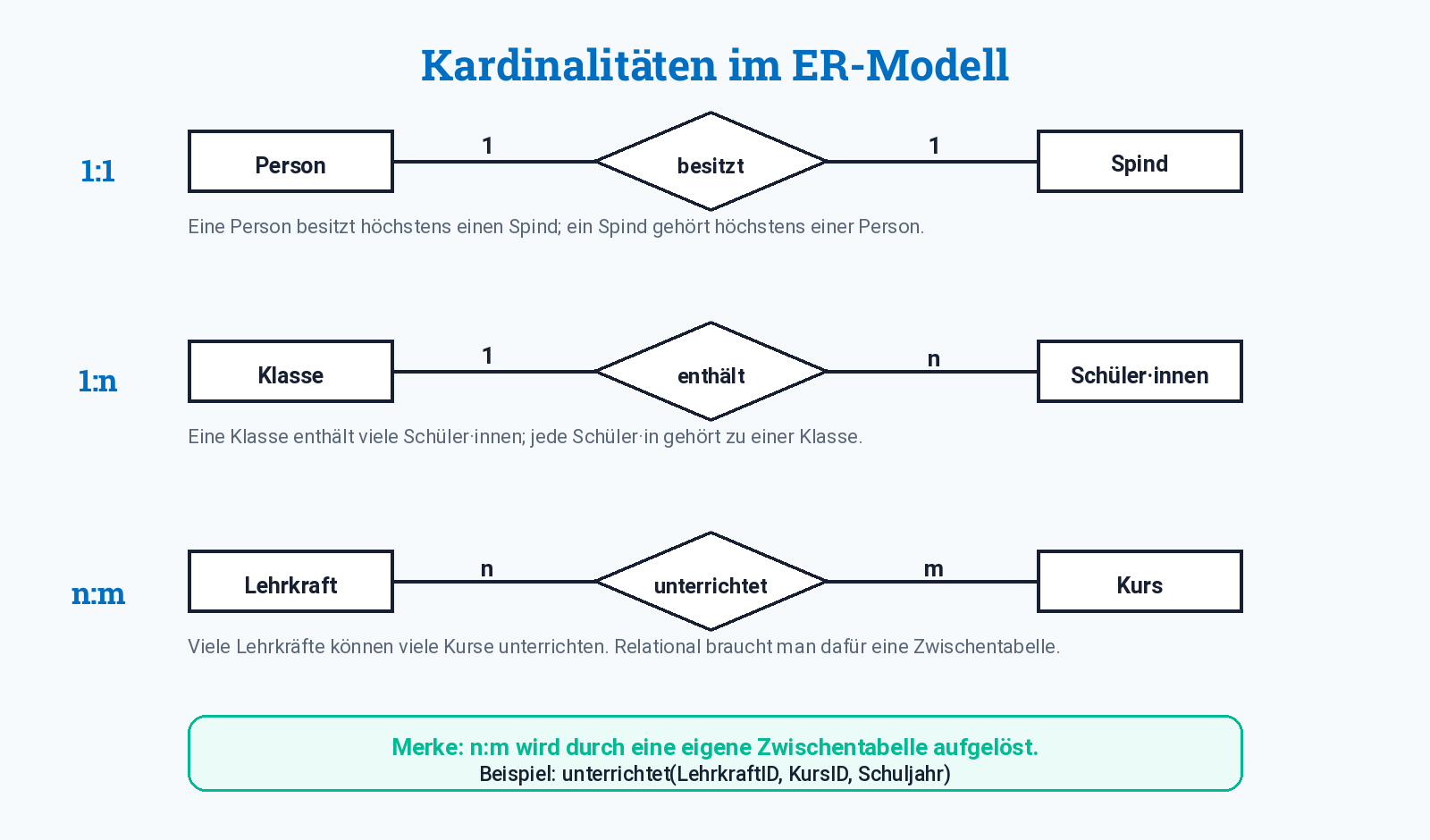
Merksatz
Eine n:m-Beziehung wird in relationalen Datenbanken durch eine eigene Zwischentabelle umgesetzt.
📝 Übung: Kardinalitäten begründen
Bestimme die Kardinalität und begründe sie jeweils in zwei Sätzen.
- Eine Klasse besteht aus mehreren Schüler·innen. Eine Schüler·in gehört genau zu einer Klasse.
- Eine Person kann mehrere Bücher ausleihen. Eine konkrete Ausleihe gehört genau zu einer Person.
- Eine Schüler·in kann mehrere Freifächer besuchen. Ein Freifach kann von mehreren Schüler·innen besucht werden.
- Ein nummerierter Spind ist genau einer Person zugeordnet. Eine Person hat höchstens einen Spind.
Lösung
- Klasse - Schüler·in: 1:n. Eine Klasse kann viele Schüler·innen enthalten; jede Schüler·in gehört zu genau einer Klasse.
- Person - Ausleihe: 1:n. Eine Person kann viele Ausleihen haben; jede Ausleihe gehört zu genau einer Person.
- Schüler·in - Freifach: n:m. Eine Schüler·in kann mehrere Freifächer besuchen; ein Freifach kann mehrere Schüler·innen haben.
- Person - Spind: 1:1. Ein Spind gehört höchstens einer Person; eine Person hat höchstens einen Spind.
Vom ER-Modell zum relationalen Modell
Nach der konzeptionellen Modellierung wird das ER-Modell in Tabellen übertragen. Dabei ist entscheidend, wo der Fremdschlüssel gespeichert wird.
Grundregeln:
- Jeder Entitätstyp wird zu einer eigenen Tabelle.
- Einfache Attribute werden zu Spalten.
- Schlüsselattribute werden zu Primärschlüsseln.
- 1:n-Beziehungen werden durch einen Fremdschlüssel auf der n-Seite umgesetzt.
- n:m-Beziehungen werden durch eine eigene Zwischentabelle umgesetzt.
- Attribute einer Beziehung werden in der Beziehungstabelle oder auf der passenden Seite gespeichert.
- Bei 1:1-Beziehungen muss begründet entschieden werden, in welcher Tabelle der Fremdschlüssel gespeichert wird.
Schreibweise im Relationenschema
In den folgenden Beispielen gilt:
- Primärschlüssel sind unterstrichen.
- Fremdschlüssel sind kursiv mit Pfeil markiert: ↑ Fremdschlüssel.
1:1-Beziehung
Bei einer 1:1-Beziehung gehört ein Datensatz der einen Tabelle höchstens zu einem Datensatz der anderen Tabelle und umgekehrt.
ER-Idee:
txt
Person besitzt SpindEine Person besitzt höchstens einen Spind. Ein Spind ist höchstens einer Person zugeordnet.
Mögliches relationales Schema:
Person(PersonID, Vorname, Nachname)
Spind(SpindID, Standort, ↑ PersonID)
Der Fremdschlüssel ↑ PersonID steht hier in Spind, weil man dadurch direkt speichern kann, welcher Spind welcher Person zugeordnet ist.
Eine alternative Modellierung wäre ebenfalls möglich:
Person(PersonID, Vorname, Nachname, ↑ SpindID)
Spind(SpindID, Standort)
Welche Variante sinnvoller ist, hängt vom Sachverhalt ab:
- Hat jede Person sicher einen Spind? Dann kann der Fremdschlüssel gut bei
Personstehen. - Gibt es viele Personen ohne Spind, aber jeder vergebene Spind gehört genau einer Person? Dann ist der Fremdschlüssel oft in
Spindsinnvoller. - Wenn die Beziehung zusätzliche Daten hat, etwa
Zuteilungsdatum, kann auch eine eigene Beziehungstabelle sinnvoll sein.
Wichtig
Bei 1:1-Beziehungen gibt es nicht immer nur eine einzig richtige Lösung. Man muss begründen, welche Tabelle den Fremdschlüssel sinnvoll „erbt“.
1:n-Beziehung
Bei einer 1:n-Beziehung kann ein Datensatz auf der 1-Seite mit mehreren Datensätzen auf der n-Seite verbunden sein. Jeder Datensatz auf der n-Seite gehört aber genau zu einem Datensatz auf der 1-Seite.
ER-Idee:
txt
Klasse enthält Schüler·innenEine Klasse enthält viele Schüler·innen. Eine Schüler·in gehört genau zu einer Klasse.
Relationales Schema:
Klasse(KlasseID, Klassenname, Raum)
Schueler(SchuelerID, Vorname, Nachname, ↑ KlasseID)
Der Fremdschlüssel ↑ KlasseID steht in der Tabelle Schueler.
Warum?
- Auf der n-Seite gibt es viele Schüler·innen.
- Jeder einzelne Schülerdatensatz kann mit einem Fremdschlüssel auf genau eine Klasse zeigen.
- Würde man alle Schüler·innen in der Tabelle
Klassespeichern, müsste man mehrere Werte in einem Feld ablegen. Das wäre unübersichtlich und nicht atomar.
Merke
Bei 1:n-Beziehungen wird der Fremdschlüssel auf der n-Seite gespeichert.
Weiteres Beispiel:
ER-Idee:
txt
Instrument wird in Kursen angebotenEin Instrument kann in mehreren Kursen vorkommen. Jeder Kurs gehört zu genau einem Instrument.
Instrument(InstrumentID, Bezeichnung)
Kurs(KursID, Kursname, Wochentag, ↑ InstrumentID)
Hier steht ↑ InstrumentID in Kurs, weil viele Kurse zu einem Instrument gehören können.
n:m-Beziehung
Bei einer n:m-Beziehung können mehrere Datensätze der einen Tabelle mit mehreren Datensätzen der anderen Tabelle verbunden sein.
ER-Idee:
txt
Schüler·innen besuchen KurseEine Schüler·in kann mehrere Kurse besuchen. Ein Kurs kann von mehreren Schüler·innen besucht werden.
Direkt in einer der beiden Tabellen wäre das problematisch:
txt
Schueler(SchuelerID, Vorname, Nachname, Kurs1, Kurs2, Kurs3)Diese Struktur wäre unflexibel, weil eine Schüler·in vielleicht einen, drei oder zehn Kurse besucht. Außerdem würden mehrere ähnliche Spalten entstehen.
Deshalb wird eine Zwischentabelle erstellt.
Relationales Schema:
Schueler(SchuelerID, Vorname, Nachname)
Kurs(KursID, Kursname)
besucht(↑ SchuelerID, ↑ KursID)
Die Tabelle besucht enthält die Fremdschlüssel beider Tabellen. Gemeinsam bilden ↑ SchuelerID und ↑ KursID den zusammengesetzten Primärschlüssel der Zwischentabelle.
Merke
Bei n:m-Beziehungen entsteht eine neue Tabelle. Die Fremdschlüssel beider beteiligter Tabellen werden in diese Zwischentabelle übernommen.
n:m-Beziehung mit Beziehungsattribut
Manchmal hat nicht nur eine Entität Eigenschaften, sondern auch die Beziehung selbst.
ER-Idee:
txt
Schüler·in besucht KursZusatzinformation:
txt
Anmeldedatum
StatusDas Anmeldedatum gehört nicht nur zur Schüler·in und auch nicht nur zum Kurs. Es beschreibt die konkrete Teilnahme einer bestimmten Schüler·in an einem bestimmten Kurs.
Relationales Schema:
Schueler(SchuelerID, Vorname, Nachname)
Kurs(KursID, Kursname)
besucht(↑ SchuelerID, ↑ KursID, Anmeldedatum, Status)
Anmeldedatum und Status stehen in der Zwischentabelle, weil sie zur Beziehung besucht gehören.
1:n-Beziehung mit Beziehungsattribut
Auch eine 1:n-Beziehung kann ein eigenes Attribut haben.
ER-Idee:
txt
Lehrkraft betreut ProjektEine Lehrkraft kann mehrere Projekte betreuen. Jedes Projekt hat genau eine hauptverantwortliche Lehrkraft. Zusätzlich soll gespeichert werden, seit wann die Betreuung besteht.
Relationales Schema:
Lehrkraft(LehrkraftID, Vorname, Nachname)
Projekt(ProjektID, Projekttitel, ↑ LehrkraftID, BetreutSeit)
Der Fremdschlüssel steht auf der n-Seite, also in Projekt. Das Beziehungsattribut BetreutSeit kann ebenfalls dort gespeichert werden, weil jede Projektzeile genau eine betreuende Lehrkraft beschreibt.
Übersicht: Wohin kommt der Fremdschlüssel?
| Beziehung im ER-Modell | Umsetzung im relationalen Modell | Wohin kommt der Fremdschlüssel? |
|---|---|---|
| 1:1 | Fremdschlüssel in einer der beiden Tabellen | in die fachlich passendere Tabelle; Entscheidung begründen |
| 1:n | Fremdschlüssel auf der n-Seite | in die Tabelle, von der viele Datensätze zu einem Datensatz gehören |
| n:m | eigene Zwischentabelle | beide Fremdschlüssel in die Zwischentabelle |
| n:m mit Beziehungsattributen | eigene Zwischentabelle mit Zusatzattributen | beide Fremdschlüssel und die Beziehungsattribute in die Zwischentabelle |
| 1:n mit Beziehungsattribut | meist Speicherung auf der n-Seite | Fremdschlüssel und Beziehungsattribut auf der n-Seite |
Typische Denkfragen beim Überführen
Beim Übertragen eines ER-Modells in ein Relationenschema helfen diese Fragen:
- Welche Entitätstypen werden zu Tabellen?
- Welche Attribute gehören eindeutig zu welcher Tabelle?
- Welches Attribut identifiziert jeden Datensatz eindeutig?
- Liegt eine 1:1-, 1:n- oder n:m-Beziehung vor?
- Muss eine eigene Zwischentabelle erstellt werden?
- Gibt es Attribute, die nicht zu einer Entität, sondern zur Beziehung gehören?
- Wo entstehen sonst Mehrfachwerte oder Redundanzen?
📝 Übung: Beziehung in Relationenschema übertragen
Überführe jeweils die ER-Idee in ein Relationenschema. Markiere Primärschlüssel und Fremdschlüssel passend.
- Eine Person besitzt höchstens eine Fahrradkarte. Eine Fahrradkarte gehört höchstens einer Person.
- Eine Klasse enthält viele Schüler·innen. Eine Schüler·in gehört genau zu einer Klasse.
- Viele Schüler·innen besuchen viele Arbeitsgemeinschaften. Zu jeder Teilnahme soll das Eintrittsdatum gespeichert werden.
Lösungsskizze
Mögliche Lösung für 1:1:
Person(PersonID, Vorname, Nachname)
Fahrradkarte(KartenID, GueltigBis, ↑ PersonID)
Mögliche Lösung für 1:n:
Klasse(KlasseID, Klassenname, Raum)
Schueler(SchuelerID, Vorname, Nachname, ↑ KlasseID)
Mögliche Lösung für n:m mit Beziehungsattribut:
Schueler(SchuelerID, Vorname, Nachname)
AG(AGID, Bezeichnung)
nimmt_teil(↑ SchuelerID, ↑ AGID, Eintrittsdatum)
Die n:m-Beziehung wird durch nimmt_teil aufgelöst. Das Eintrittsdatum gehört zur konkreten Teilnahme und steht deshalb in der Zwischentabelle.
📝 Übung: ER-Modell in Relationenschema übertragen
Ein Musikschul-System verwaltet Schüler·innen, Instrumente und Kurse.
Sachverhalt:
- Eine Schüler·in kann mehrere Kurse besuchen.
- Ein Kurs kann von mehreren Schüler·innen besucht werden.
- Jeder Kurs gehört genau zu einem Instrument.
- Ein Instrument kann in mehreren Kursen angeboten werden.
- Zu jeder Kursteilnahme soll das Anmeldedatum gespeichert werden.
Aufgaben:
- Bestimme die Entitätstypen.
- Bestimme die Beziehungstypen und Kardinalitäten.
- Überführe das Modell in ein Relationenschema.
Lösungsskizze
Entitätstypen:
txt
Schueler
Kurs
InstrumentBeziehungen:
txt
Schueler besucht Kurs n:m
Kurs gehört zu Instrument n:1Mögliches Relationenschema:
Schueler(SchuelerID, Vorname, Nachname)
Instrument(InstrumentID, Bezeichnung)
Kurs(KursID, Kursname, ↑ InstrumentID)
besucht(↑ SchuelerID, ↑ KursID, Anmeldedatum)
↑ InstrumentID steht in Kurs, weil jeder Kurs genau einem Instrument zugeordnet ist. Die n:m-Beziehung zwischen Schüler·innen und Kursen wird durch besucht umgesetzt. Das Anmeldedatum beschreibt die konkrete Teilnahme und gehört deshalb ebenfalls in die Zwischentabelle.
Normalisierung
Normalisierung bedeutet, Tabellen so zu strukturieren, dass Daten möglichst eindeutig, widerspruchsarm und flexibel gespeichert werden.
Dabei geht es vor allem darum:
- Redundanzen zu vermeiden,
- atomare Werte zu verwenden,
- Abhängigkeiten sauber zu ordnen,
- Einfüge-, Änderungs- und Löschprobleme zu vermeiden.
Redundanz und Inkonsistenz
Redundanz bedeutet, dass dieselbe Information mehrfach gespeichert ist.
Beispiel:
| AusleiheID | Person | Klasse | Klassenraum | Buch |
|---|---|---|---|---|
| 1 | Sara | 6A | 204 | Momo |
| 2 | Lukas | 6A | 204 | Krabat |
| 3 | Mina | 6A | 204 | Rico, Oskar und die Tieferschatten |
Der Klassenraum 204 wird mehrfach gespeichert. Wenn sich der Raum der 6A ändert, muss jede Zeile geändert werden.
Inkonsistenz entsteht, wenn redundante Informationen nicht überall gleich geändert werden.
| AusleiheID | Person | Klasse | Klassenraum | Buch |
|---|---|---|---|---|
| 1 | Sara | 6A | 204 | Momo |
| 2 | Lukas | 6A | 207 | Krabat |
Jetzt ist unklar, welcher Raum zur 6A gehört.
Merke
Redundanz ist nicht nur ein Speicherproblem. Sie kann zu widersprüchlichen Daten führen.
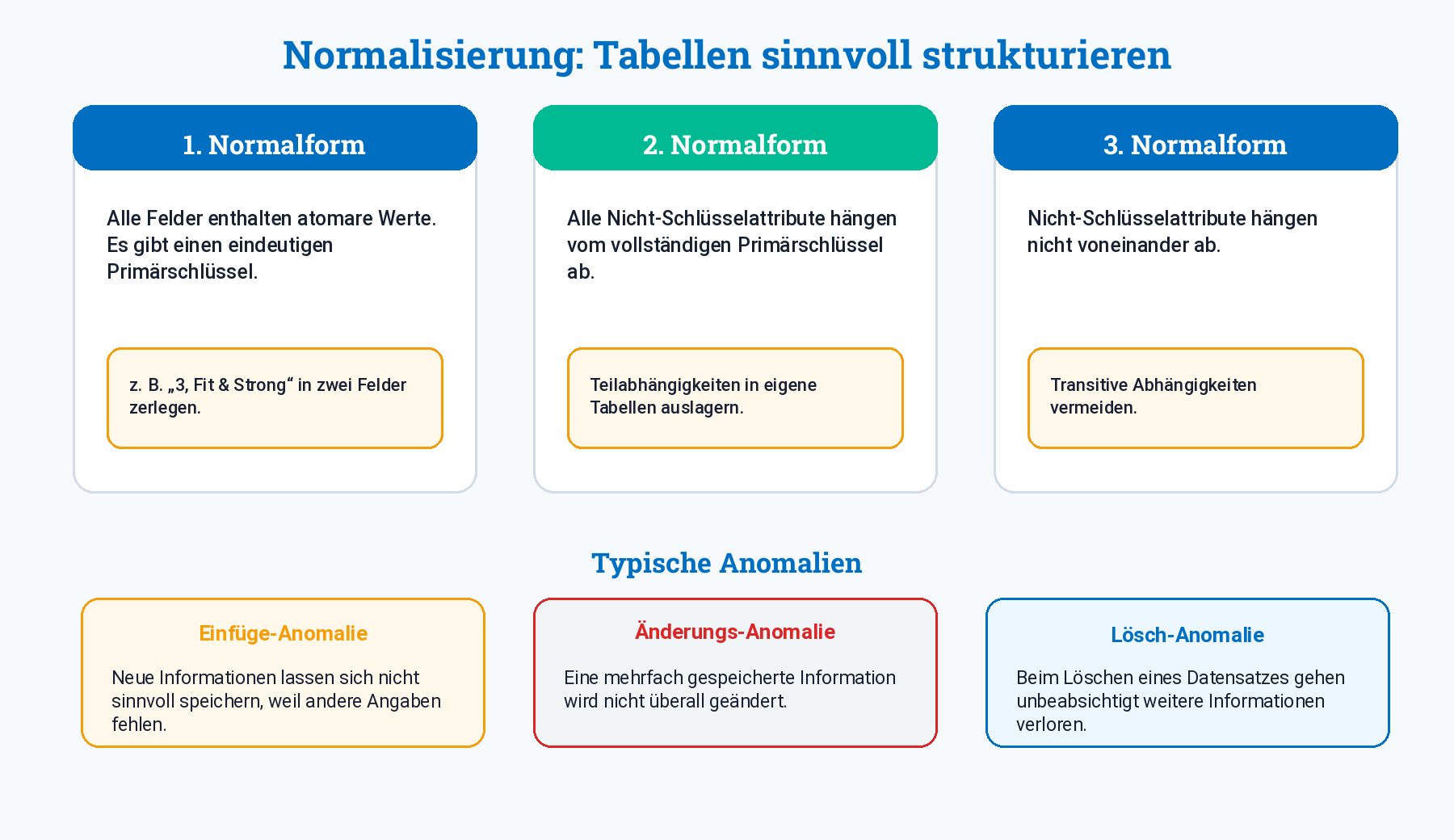
Anomalien
Anomalien sind unerwünschte Effekte, die bei schlecht strukturierten Tabellen auftreten können.
Änderungs-Anomalie
Eine Information ist mehrfach gespeichert und muss an mehreren Stellen geändert werden.
Beispiel:
In vielen Zeilen steht, dass die Klasse 6A im Raum 204 ist. Der Raum ändert sich auf 207. Wird nur ein Teil der Zeilen geändert, entstehen widersprüchliche Daten.
Einfüge-Anomalie
Neue Informationen können nicht sinnvoll gespeichert werden, weil andere Daten noch fehlen.
Beispiel:
Eine neue Klasse 7C soll mit Raum 305 gespeichert werden. In der Tabelle können Klassen aber nur gemeinsam mit einer Ausleihe gespeichert werden. Wenn noch keine Ausleihe existiert, kann die Klasse nicht sauber eingetragen werden.
Lösch-Anomalie
Beim Löschen eines Datensatzes gehen unbeabsichtigt zusätzliche Informationen verloren.
Beispiel:
Die letzte Ausleihe einer Klasse wird gelöscht. Dadurch verschwindet auch die einzige gespeicherte Information darüber, in welchem Raum diese Klasse ist.
Wichtig
Anomalien zeigen, dass in einer Tabelle Informationen vermischt wurden, die eigentlich in getrennte Tabellen gehören.
Funktionale Abhängigkeit
Eine funktionale Abhängigkeit beschreibt, dass ein Wert einen anderen Wert eindeutig bestimmt.
Schreibweise:
txt
A -> BDas bedeutet:
Wenn ich A kenne, kenne ich auch B.
Beispiele:
txt
KlasseID -> Klassenname
KlasseID -> Raum
BuchID -> Titel
ProduktID -> PreisWenn KlasseID eindeutig ist, bestimmt sie den Klassennamen und den Raum. Wenn diese Informationen in vielen anderen Tabellen wiederholt werden, entstehen Redundanzen.
Normalformen
Normalformen sind Regeln, mit denen Tabellen schrittweise verbessert werden.
Erste Normalform (1NF)
Eine Tabelle befindet sich in der ersten Normalform, wenn:
- alle Attribute atomar sind,
- jedes Feld nur einen einzelnen Wert enthält,
- ein eindeutiger Primärschlüssel vorhanden ist.
Nicht atomar:
| PersonID | Name | Kurse |
|---|---|---|
| 1 | Sara Demir | Informatik, Geschichte, Biologie |
Problem: In Kurse stehen mehrere Werte in einem Feld.
Besser:
txt
Person(PersonID, Vorname, Nachname)
Kurs(KursID, Kursname)
besucht(PersonID, KursID)Merksatz
Ein Feld soll nicht mehrere unabhängige Informationen enthalten.
Zweite Normalform (2NF)
Die zweite Normalform ist vor allem bei zusammengesetzten Primärschlüsseln wichtig.
Eine Tabelle befindet sich in der zweiten Normalform, wenn:
- sie in der ersten Normalform ist,
- jedes Nicht-Schlüsselattribut vom vollständigen Primärschlüssel abhängt.
Problembeispiel:
txt
Teilnahme(PersonID, KursID, Personenname, Kursname, Anmeldedatum)Angenommen, der Primärschlüssel ist (PersonID, KursID).
Personennamehängt nur vonPersonIDab.Kursnamehängt nur vonKursIDab.Anmeldedatumhängt von der Kombination ausPersonIDundKursIDab.
Besser:
txt
Person(PersonID, Personenname)
Kurs(KursID, Kursname)
Teilnahme(PersonID, KursID, Anmeldedatum)Dritte Normalform (3NF)
Eine Tabelle befindet sich in der dritten Normalform, wenn:
- sie in der ersten und zweiten Normalform ist,
- Nicht-Schlüsselattribute nicht voneinander abhängen.
Problembeispiel:
txt
Schueler(SchuelerID, Name, KlasseID, Klassenname, Klassenraum)Klassenname und Klassenraum hängen nicht direkt von der Schüler·in ab, sondern von KlasseID.
Besser:
txt
Schueler(SchuelerID, Name, KlasseID)
Klasse(KlasseID, Klassenname, Klassenraum)Merke
Normalisierung bedeutet nicht, Tabellen möglichst kompliziert zu machen. Sie bedeutet, Informationen dort zu speichern, wo sie fachlich hingehören.
📝 Übung: Anomalien erkennen
Gegeben ist folgende Tabelle:
| BestellungID | Kundin | Adresse | Produkt | Kategorie | Kategorienleitung |
|---|---|---|---|---|---|
| 1 | Mina Berger | Hauptstraße 4 | Heft | Schreibwaren | Herr Paul |
| 2 | Mina Berger | Hauptstraße 4 | Stift | Schreibwaren | Herr Paul |
| 3 | Sara Demir | Schulstraße 8 | Ball | Sport | Frau Novak |
- Wo gibt es Redundanzen?
- Welche Änderungs-Anomalie könnte auftreten?
- Welche Lösch-Anomalie könnte auftreten?
- Skizziere eine bessere Tabellenstruktur.
Lösungshinweis
Redundanzen: Kundendaten können mehrfach vorkommen; Kategorienleitung wird bei jedem Produkt der Kategorie wiederholt.
Änderungs-Anomalie: Ändert sich die Leitung der Kategorie Schreibwaren, muss sie in mehreren Zeilen geändert werden.
Lösch-Anomalie: Wird der letzte Sportartikel gelöscht, könnte auch die Information verloren gehen, dass Frau Novak die Kategorie Sport leitet.
Mögliche Aufteilung:
txt
Kunde(KundenID, Name, Adresse)
Kategorie(KategorieID, Bezeichnung, Leitung)
Produkt(ProduktID, Produktname, KategorieID)
Bestellung(BestellungID, KundenID)
Bestellposition(BestellungID, ProduktID)📝 Übung: Normalformen anwenden
Eine Tabelle für eine Projektwoche sieht so aus:
txt
Projektwahl(SchuelerID, Name, Klasse, ProjektID, Projekttitel, Projektleitung, Raum)Ein·e Schüler·in kann genau ein Projekt wählen. Ein Projekt hat eine Projektleitung und findet in einem Raum statt.
- Erkläre, welche Informationen mehrfach vorkommen können.
- Begründe, warum die Tabelle nicht gut normalisiert ist.
- Teile die Tabelle sinnvoll auf.
Lösungsskizze
Mehrfach vorkommen können Projekttitel, Projektleitung und Raum für alle Schüler·innen desselben Projekts. Auch Klasse könnte für viele Schüler·innen wiederholt werden.
Mögliche Aufteilung:
txt
Klasse(KlasseID, Klassenname)
Schueler(SchuelerID, Name, KlasseID, ProjektID)
Projekt(ProjektID, Projekttitel, Projektleitung, Raum)Wenn Räume ebenfalls unabhängig verwaltet werden sollen:
txt
Raum(RaumID, Raumname)
Projekt(ProjektID, Projekttitel, Projektleitung, RaumID)Automatisierte Auswertungen kritisch betrachten
Datenbanken ermöglichen nicht nur Speicherung und Suche, sondern auch automatische Kategorisierung und Auswertung.
Das kann hilfreich sein, etwa für:
- schnellere Organisation,
- gezielte Informationen,
- bessere Planung,
- automatische Zusammenfassungen,
- Empfehlungssysteme.
Es kann aber problematisch werden, wenn:
- Menschen auf wenige Datenpunkte reduziert werden,
- sensible Merkmale verwendet werden,
- Kategorien zu grob sind,
- Vorurteile in Regeln eingebaut werden,
- Entscheidungen nicht transparent sind,
- Nutzer·innen keine echte Kontrolle über ihre Daten haben.
CASE-Query als Entscheidungsstruktur
Mit CASE kann eine SQL-Abfrage abhängig von Bedingungen unterschiedliche Werte ausgeben. Man kann sich das ähnlich wie eine Wenn-Dann-Sonst-Entscheidung vorstellen.
Unproblematisches Beispiel:
sql
SELECT
PersonID,
Punkte,
CASE
WHEN Punkte >= 100 THEN 'sehr aktiv'
WHEN Punkte >= 50 THEN 'aktiv'
ELSE 'neu'
END AS Status
FROM Lernplattform;Diese Abfrage ordnet Personen anhand eines Punktestands einer Statusgruppe zu.
Problematisch wird es, wenn sensible oder stereotype Annahmen in die Bedingungen eingebaut werden.

Wichtig
Eine CASE-Abfrage ist technisch nur eine Entscheidungsstruktur. Ob sie fair und verantwortungsvoll ist, hängt davon ab, welche Daten verwendet werden und welche Annahmen in den Bedingungen stecken.
Datenschutzbezug
Bei personenbezogenen Daten sind besonders wichtig:
- Zweckbindung: Daten dürfen nur für einen klaren Zweck verwendet werden.
- Datenminimierung: Es sollen nur notwendige Daten verarbeitet werden.
- Transparenz: Betroffene sollen wissen, welche Daten verarbeitet werden.
- Erforderlichkeit: Die Datenverarbeitung muss für den Zweck notwendig sein.
- rechtmäßige Grundlage: Verarbeitung braucht Zustimmung oder eine gesetzliche Grundlage.
Merke
Technisch mögliche Auswertungen sind nicht automatisch rechtlich oder ethisch vertretbar.
📝 Übung: CASE-Query kritisch beurteilen
Eine Lernplattform verwendet folgende Abfrage:
sql
SELECT
NutzerID,
Fehlversuche,
Bearbeitungszeit,
CASE
WHEN Fehlversuche > 10 AND Bearbeitungszeit < 5 THEN 'riskiert Abbruch'
WHEN Fehlversuche <= 3 THEN 'sicher'
ELSE 'beobachten'
END AS Lernstatus
FROM Uebungsdaten;- Beschreibe, was die Abfrage technisch macht.
- Erkläre, warum die Einteilung problematisch sein könnte.
- Formuliere zwei Regeln für einen verantwortungsvolleren Einsatz.
Lösungshinweis
Die Abfrage ordnet Nutzer·innen anhand von Fehlversuchen und Bearbeitungszeit einem Lernstatus zu.
Problematisch ist, dass aus wenigen Messwerten weitreichende Aussagen über Lernverhalten abgeleitet werden. Kurze Bearbeitungszeit kann viele Gründe haben. Viele Fehlversuche können auch auf Ausprobieren, Sprachprobleme, Müdigkeit oder ein unpassendes Aufgabenformat hinweisen.
Regeln: Kriterien transparent machen, menschliche Kontrolle vorsehen, keine automatischen Nachteile ableiten, nur notwendige Daten verwenden, Ergebnisse als Hinweis und nicht als endgültiges Urteil behandeln.
Typische Missverständnisse
„Eine Datenbank ist einfach eine große Excel-Tabelle.“
Nicht ganz. Datenbanken arbeiten mit Schlüsseln, Beziehungen, Zugriffsrechten, Abfragen, Integritätsregeln und oft mit vielen gleichzeitigen Nutzer·innen.
„Wenn Daten in Tabellen stehen, sind sie automatisch gut strukturiert.“
Nein. Auch Tabellen können schlecht aufgebaut sein. Gute Struktur entsteht durch sinnvolle Modellierung, Schlüssel und Normalisierung.
„SQL sucht einfach nur Text.“
Nein. SQL kann filtern, sortieren, gruppieren, zählen, berechnen und Tabellen verknüpfen.
„Redundanz ist egal, weil Speicher billig ist.“
Nein. Redundanz führt nicht nur zu mehr Speicherverbrauch, sondern vor allem zu Änderungsproblemen und Widersprüchen.
„Automatisierte Auswertungen sind objektiv.“
Nicht automatisch. Datenmodelle und Abfragen spiegeln menschliche Entscheidungen wider.
Prüfungsvorbereitung
Die folgenden Aufgaben trainieren dieselben Kompetenzen, verwenden aber andere Kontexte, Daten und Beispiele.
📝 Übung: Datenbanksystem begründen
Ein Sportverein verwaltet Mitglieder, Teams, Trainingszeiten, Mitgliedsbeiträge und Geräteausleihen.
- Erkläre, warum eine Tabellenkalkulation am Anfang ausreichend sein könnte.
- Begründe, warum bei wachsender Mitgliederzahl ein Datenbanksystem sinnvoller wird.
- Nenne zwei Vorteile eines zentralen DBMS.
- Erkläre, wie unterschiedliche Ansichten sinnvoll sein könnten.
Lösungshinweis
Eine Tabellenkalkulation reicht bei wenigen Mitgliedern und einfachen Listen oft aus.
Ein Datenbanksystem wird sinnvoll, wenn viele Daten miteinander verknüpft sind, mehrere Personen gleichzeitig arbeiten, Berechtigungen nötig sind oder wiederkehrende Abfragen durchgeführt werden.
Vorteile: zentrale Datenhaltung, Rechteverwaltung, gemeinsame aktuelle Datenbasis, Datensicherung, weniger Versionschaos.
Ansichten: Trainer·innen sehen Teamlisten; Kassier·innen sehen Beiträge; Mitglieder sehen nur eigene Daten.
📝 Übung: Relationenschema lesen
Gegeben ist folgendes Relationenschema:
txt
Mitglied(MitgliedID, Vorname, Nachname)
Team(TeamID, Teamname)
spielt_in(MitgliedID, TeamID, Eintrittsdatum)- Bestimme die Entitätstypen.
- Erkläre die Aufgabe der Tabelle
spielt_in. - Begründe, welcher Beziehungstyp zwischen Mitgliedern und Teams vorliegt.
- Erkläre, warum
Eintrittsdatumin der Zwischentabelle sinnvoll gespeichert ist.
Lösungshinweis
Entitätstypen sind Mitglied und Team.
spielt_in ist eine Zwischentabelle und verbindet Mitglieder mit Teams.
Es liegt eine n:m-Beziehung vor: Ein Mitglied kann in mehreren Teams spielen, und ein Team kann mehrere Mitglieder haben.
Das Eintrittsdatum beschreibt nicht das Mitglied allein und auch nicht das Team allein, sondern die konkrete Teilnahme eines Mitglieds in einem Team.
📝 Übung: SQL formulieren
Gegeben ist die Tabelle:
txt
Veranstaltung(EventID, Titel, Kategorie, Datum, Teilnehmerzahl)Formuliere SQL-Abfragen:
- Zeige alle Veranstaltungen der Kategorie
Workshop. - Zeige Titel und Datum aller Veranstaltungen ab dem 1. Juni 2026.
- Sortiere alle Veranstaltungen nach Teilnehmerzahl absteigend.
- Zähle, wie viele Veranstaltungen es pro Kategorie gibt.
- Zeige nur Kategorien mit mehr als drei Veranstaltungen.
Lösung
sql
SELECT *
FROM Veranstaltung
WHERE Kategorie = 'Workshop';sql
SELECT Titel, Datum
FROM Veranstaltung
WHERE Datum >= '2026-06-01';sql
SELECT Titel, Teilnehmerzahl
FROM Veranstaltung
ORDER BY Teilnehmerzahl DESC;sql
SELECT Kategorie, COUNT(*) AS Anzahl
FROM Veranstaltung
GROUP BY Kategorie;sql
SELECT Kategorie, COUNT(*) AS Anzahl
FROM Veranstaltung
GROUP BY Kategorie
HAVING COUNT(*) > 3;📝 Übung: Modellierung
Ein Schulfest soll digital verwaltet werden.
Sachverhalt:
- Es gibt Stände, z. B. Getränke, Kuchen, Tombola.
- Jeder Stand hat genau eine verantwortliche Klasse.
- Eine Klasse kann mehrere Stände betreuen.
- Schüler·innen können bei mehreren Ständen mithelfen.
- Ein Stand kann mehrere Helfer·innen haben.
- Für jede Mithilfe soll eine Uhrzeit gespeichert werden.
Aufgaben:
- Bestimme Entitätstypen.
- Bestimme Beziehungen und Kardinalitäten.
- Überführe das Modell in ein Relationenschema.
Lösungsskizze
Mögliche Entitätstypen:
txt
Klasse
Stand
SchuelerBeziehungen:
txt
Klasse betreut Stand 1:n
Schueler hilft_bei Stand n:mMögliches Relationenschema:
txt
Klasse(KlasseID, Klassenname)
Stand(StandID, Bezeichnung, KlasseID)
Schueler(SchuelerID, Vorname, Nachname, KlasseID)
hilft_bei(SchuelerID, StandID, Uhrzeit)hilft_bei ist die Zwischentabelle für die n:m-Beziehung zwischen Schüler·innen und Ständen.
📝 Übung: Normalisierung und Anomalien
Eine Tabelle zur Verwaltung von Schulfestständen sieht so aus:
txt
Standplan(StandID, Standname, Klasse, Klassenvorstand, Schueler1, Schueler2, Raum, Bereich)- Erkläre, warum diese Tabelle problematisch ist.
- Nenne mögliche Einfüge-, Änderungs- und Lösch-Anomalien.
- Überarbeite die Struktur in mehrere Tabellen.
Lösungshinweis
Problematisch sind unter anderem Schueler1 und Schueler2, weil mehrere Werte als feste Spalten modelliert werden. Außerdem können Klasse und Klassenvorstand mehrfach gespeichert werden.
Mögliche bessere Struktur:
txt
Klasse(KlasseID, Klassenname, Klassenvorstand)
Stand(StandID, Standname, Raum, Bereich, KlasseID)
Schueler(SchuelerID, Vorname, Nachname, KlasseID)
hilft_bei(SchuelerID, StandID)Damit werden Stände, Klassen, Schüler·innen und Mithilfe sauber getrennt.
Ich kann …
Nach der Wiederholung dieses Themenbereichs solltest du Folgendes können:
- Ich kann erklären, wofür relationale Datenbanken eingesetzt werden.
- Ich kann Tabellenkalkulationsprogramme und Datenbanksysteme vergleichen.
- Ich kann begründen, warum Datenbanken häufig zentral verwaltet werden.
- Ich kann die Rolle des DBMS beschreiben.
- Ich kann erklären, was mit unterschiedlichen Ansichten auf Daten gemeint ist.
- Ich kann Tabelle, Datensatz, Attribut, Attributwert und Relationenschema erklären.
- Ich kann Primärschlüssel und Fremdschlüssel unterscheiden.
- Ich kann einfache Relationenschemata lesen und interpretieren.
- Ich kann einfache SQL-Abfragen mit
SELECT,FROM,WHEREundORDER BYlesen und formulieren. - Ich kann Bedingungen mit Vergleichsoperatoren,
AND,OR,NOT,LIKE,BETWEENundINanwenden. - Ich kann Aggregatfunktionen wie
COUNT,SUM,AVG,MINundMAXerklären. - Ich kann
GROUP BYundHAVINGunterscheiden. - Ich kann Tabellen mithilfe von Schlüsseln verknüpfen.
- Ich kann den Ablauf der Datenbankentwicklung von der Anforderung bis zur Umsetzung beschreiben.
- Ich kann Entität, Entitätstyp, Attribut, Attributwert und Beziehung erklären.
- Ich kann 1:1-, 1:n- und n:m-Beziehungen erkennen und begründen.
- Ich kann ein einfaches ER-Modell in ein Relationenschema übertragen.
- Ich kann erklären, warum n:m-Beziehungen mit Zwischentabellen umgesetzt werden.
- Ich kann Redundanz und Inkonsistenz unterscheiden.
- Ich kann Einfüge-, Änderungs- und Lösch-Anomalien erklären.
- Ich kann die Grundidee der ersten, zweiten und dritten Normalform beschreiben.
- Ich kann schlecht strukturierte Tabellen sinnvoll aufteilen.
- Ich kann CASE-Queries als Entscheidungsstrukturen verstehen und kritisch beurteilen.
- Ich kann technische, organisatorische und ethische Aspekte beim Umgang mit Daten reflektieren.
Mini-Check
Beantworte zum Abschluss kurz:
- Was ist der Unterschied zwischen Datenbank, DBMS und Datenbanksystem?
- Warum ist eine Tabellenkalkulation nicht automatisch ein Datenbanksystem?
- Was ist ein Primärschlüssel?
- Was ist ein Fremdschlüssel?
- Was ist ein Relationenschema?
- Was ist der Unterschied zwischen Projektion und Selektion?
- Wofür verwendet man
WHERE? - Wofür verwendet man
GROUP BY? - Worin unterscheidet sich
WHEREvonHAVING? - Warum braucht man bei n:m-Beziehungen eine Zwischentabelle?
- Was ist eine funktionale Abhängigkeit?
- Was bedeutet atomar im Zusammenhang mit der ersten Normalform?
- Was ist eine Änderungs-Anomalie?
- Was ist eine Lösch-Anomalie?
- Warum ist Redundanz nicht nur ein Speicherproblem?
- Warum sind automatisierte Datenbankauswertungen nicht automatisch objektiv?
Kurzlösungen
- Die Datenbank enthält die Daten; das DBMS verwaltet sie; das Datenbanksystem umfasst beides gemeinsam.
- Eine Tabellenkalkulation ist vor allem für Berechnungen und kleinere Listen gedacht; ein Datenbanksystem verwaltet strukturierte, verknüpfte und oft gemeinsam genutzte Daten.
- Ein Primärschlüssel identifiziert jeden Datensatz eindeutig.
- Ein Fremdschlüssel verweist auf einen Primärschlüssel einer anderen Tabelle.
- Ein Relationenschema beschreibt eine Tabelle mit ihren Attributen in Kurzform.
- Projektion wählt Spalten aus; Selektion wählt Zeilen aus.
WHEREfiltert einzelne Datensätze anhand einer Bedingung.GROUP BYfasst Datensätze mit gleichen Werten zu Gruppen zusammen.WHEREfiltert vor der Gruppierung;HAVINGfiltert nach der Gruppierung.- Weil relationale Datenbanken n:m-Beziehungen über zwei 1:n-Beziehungen abbilden.
- Ein Wert bestimmt einen anderen Wert eindeutig, z. B.
KlasseID -> Klassenraum. - Ein Feld enthält genau einen unteilbaren Wert und keine Liste oder zusammengesetzte Information.
- Eine Information muss mehrfach geändert werden; wird eine Stelle vergessen, entstehen Widersprüche.
- Beim Löschen eines Datensatzes gehen unbeabsichtigt weitere Informationen verloren.
- Redundanz kann zu Inkonsistenzen und Änderungsfehlern führen.
- Weil Kategorien, Datenbasis und Abfragelogik von Menschen festgelegt werden und Vorannahmen enthalten können.