Appearance
🎓 Thema 12: Intelligente Systeme (KI)
Überblick
Künstliche Intelligenz begegnet dir in Suchmaschinen, Übersetzungsprogrammen, Empfehlungssystemen, Bildanalyse, Spamfiltern, Navigationssystemen und Chatbots. Wichtig ist dabei nicht nur, dass ein System „intelligent wirkt“. Du solltest auch erklären können, wie ein System zu Entscheidungen kommt, welche Daten dafür notwendig sind und welche Grenzen solche Entscheidungen haben.
Leitfrage
Wie können Informatiksysteme aus Daten oder Regeln Entscheidungen ableiten – und warum müssen Menschen diese Entscheidungen trotzdem kritisch prüfen?
Du solltest nach der Wiederholung erklären können,
- was mit künstlicher Intelligenz gemeint ist und warum es keine einfache, allgemeingültige Definition gibt,
- wodurch sich schwache und starke KI unterscheiden,
- wie der Turing-Test funktioniert und welche Aussagekraft er hat,
- was wissensbasierte und datenbasierte KI-Systeme unterscheidet,
- welche Grundideen hinter überwachtem, unüberwachtem und verstärkendem Lernen stehen,
- wie der k-nächste-Nachbarn-Algorithmus neue Datenpunkte klassifiziert,
- warum die Wahl von
k, die Merkmalsauswahl und das Abstandsmaß wichtig sind, - wie Entscheidungsbäume aufgebaut sind und wie sie zur Klassifikation genutzt werden,
- was Hyperparameter, Trainingsdaten, Validierungsdaten, Testdaten, Overfitting und Underfitting bedeuten,
- wie ein künstliches Neuron grundsätzlich arbeitet,
- warum neuronale Netze leistungsfähig, aber oft schwer nachvollziehbar sind,
- welche Chancen, Risiken und Verantwortungsfragen beim Einsatz von KI entstehen.
Das Themenfeld im Zusammenhang
Das Themenfeld Intelligente Systeme verbindet mehrere Ebenen: Grundbegriffe rund um künstliche Intelligenz, unterschiedliche Arten des maschinellen Lernens, konkrete Verfahren wie k-NN und Entscheidungsbäume, mathematisch-technische Orientierung wie Abstandsmaße, Informationsgewinn oder Gini-Unreinheit, sowie Fragen nach Nachvollziehbarkeit, Fairness und Verantwortung.
Im Unterricht ist dabei wichtig: Du sollst nicht jedes Verfahren auf Universitätsniveau herleiten können. Du solltest aber verstehen, welches Problem ein Verfahren löst, wie es grundsätzlich arbeitet, welche Stellschrauben wichtig sind und wo typische Grenzen liegen. Gerade bei k-NN und Entscheidungsbäumen hilft ein kurzer Blick auf die zugrunde liegenden mathematischen Ideen, damit die Modelle nicht wie „Zauberei“ wirken.
Merke
In diesem Thema geht es nicht nur um Anwendungen von KI, sondern auch darum, wie Entscheidungen technisch zustande kommen und warum diese Entscheidungen kritisch geprüft werden müssen.
Künstliche Intelligenz: mehr als „ein schlauer Computer“
Künstliche Intelligenz beschreibt Informatiksysteme, die Aufgaben bearbeiten, die wir häufig mit menschlicher Intelligenz verbinden: Sprache verstehen, Bilder erkennen, Entscheidungen treffen, Texte erzeugen, Muster finden oder Handlungen planen.
Dabei ist wichtig: Ein System muss nicht „denken wie ein Mensch“, um als KI-System bezeichnet zu werden. Häufig reicht es, dass es eine Aufgabe löst, für die bisher menschliche Urteilsfähigkeit nötig war.
Merke
KI ist kein einzelnes Programmierverfahren. Es ist ein Sammelbegriff für unterschiedliche Ansätze, mit denen Informatiksysteme Aufgaben lösen, die intelligent wirken oder rationale Entscheidungen ermöglichen.
Schwache und starke KI
| Begriff | Bedeutung | Beispiel |
|---|---|---|
| schwache KI | Ein System ist auf eine konkrete Aufgabe spezialisiert. | Spamfilter, Übersetzungsprogramm, Bilderkennung, Navigationssystem |
| starke KI | Ein System hätte allgemeine, menschenähnliche Intelligenz über viele Bereiche hinweg. | derzeit vor allem Science-Fiction bzw. theoretisches Ziel |
Heutige KI-Systeme sind in der Regel schwache KI. Sie können in ihrem Spezialbereich sehr leistungsfähig sein, aber außerhalb dieses Bereichs schnell scheitern.
Ein Schachprogramm kann extrem stark Schach spielen. Daraus folgt aber nicht, dass es ein Formular versteht, ein Fahrrad repariert oder ein Gespräch über Freundschaft sinnvoll führen kann.
Der Turing-Test
Alan Turing schlug ein Verfahren vor, um maschinelles Verhalten zu bewerten: Eine Person kommuniziert schriftlich mit einem Menschen und einem Computerprogramm, ohne zu wissen, wer wer ist. Kann sie den Computer nicht zuverlässig erkennen, gilt das Programm im Sinne dieses Tests als intelligent.
Achtung
Der Turing-Test prüft vor allem, ob ein System menschenähnlich kommunizieren kann. Er beweist nicht, dass ein System wirklich versteht, fühlt oder bewusst denkt.
📝 Übung: Ist das schon KI?
Ordne die folgenden Systeme begründet ein: eher keine KI, schwache KI oder hypothetisch starke KI.
- Ein Taschenrechner berechnet
438 · 17. - Eine App erkennt Pflanzenarten anhand eines Fotos.
- Ein Programm schlägt dir Musik vor, weil andere Nutzer·innen mit ähnlichem Hörverhalten diese Titel mochten.
- Ein Roboter aus einem Film versteht jede Alltagssituation, lernt selbstständig, hat eigene Ziele und handelt flexibel.
- Eine Heizungssteuerung schaltet bei unter 19 °C automatisch ein.
Lösungshinweis
1 eher keine KI, weil nur eine fest definierte Rechenoperation ausgeführt wird. 2 schwache KI, weil Bilder klassifiziert werden. 3 schwache KI bzw. datenbasiertes Empfehlungssystem. 4 wäre starke KI, wenn diese Fähigkeiten wirklich allgemein vorhanden wären. 5 meist eher keine KI, wenn nur eine einfache Wenn-Dann-Regel verwendet wird; mit lernender Anpassung an Nutzungsverhalten könnte es KI-ähnlicher werden.
Wissensbasierte und datenbasierte Ansätze
KI-Systeme können auf unterschiedliche Weise entstehen. Zwei wichtige Denkweisen sind wissensbasierte und datenbasierte Ansätze.
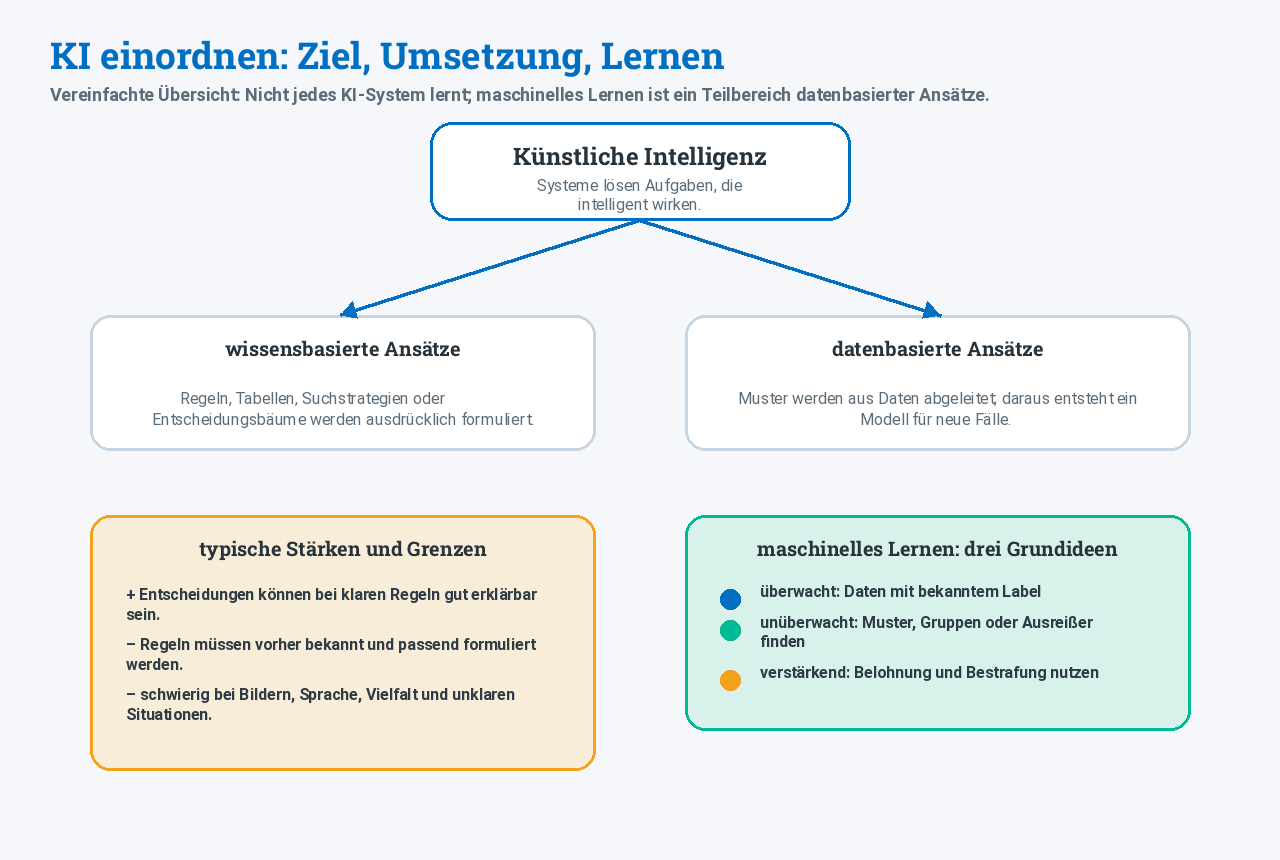
Wissensbasierte Systeme
Bei wissensbasierten Systemen formulieren Menschen das Wissen ausdrücklich: Regeln, Tabellen, Suchstrategien oder Entscheidungsbäume werden vorgegeben.
Beispiele:
- Ein Chatbot reagiert auf bestimmte Schlüsselwörter.
- Ein Expertensystem nutzt Regeln wie: „Wenn Symptom A und Symptom B auftreten, prüfe Möglichkeit C.“
- Ein Spielprogramm durchsucht mögliche Spielzüge und bewertet sie nach festgelegten Regeln.
Der Vorteil: Entscheidungen sind oft gut nachvollziehbar. Der Nachteil: Die Regeln müssen vorher bekannt sein und vollständig genug formuliert werden.
Datenbasierte Systeme
Bei datenbasierten Systemen werden Regeln nicht vollständig von Menschen vorgegeben. Stattdessen werden Daten verwendet, aus denen ein System Muster ableitet.
Beispiele:
- Ein Spamfilter lernt aus bereits markierten E-Mails.
- Ein Bilderkennungssystem lernt aus vielen gelabelten Bildern.
- Ein Empfehlungssystem erkennt Ähnlichkeiten zwischen Nutzer·innen, Filmen, Produkten oder Beiträgen.
Merksatz
Wissensbasierte KI arbeitet mit ausdrücklich formuliertem Wissen. Datenbasierte KI lernt Muster aus Beispielen oder Erfahrungen.
Drei Lernarten des maschinellen Lernens
Maschinelles Lernen bedeutet: Ein System wird nicht für jede einzelne Entscheidung direkt programmiert, sondern leitet aus Daten oder Rückmeldungen ein Modell ab.
Überwachtes Lernen
Beim überwachten Lernen sind die richtigen Ergebnisse in den Trainingsdaten bekannt. Diese Ergebnisse heißen Labels.
Beispiele:
- E-Mail: Spam oder kein Spam
- Bild: Katze, Hund oder Vogel
- Wetterdaten: hoher oder niedriger Eisverkauf
- Textbeitrag: positiv, neutral oder negativ
Das System lernt aus Beispielen und soll anschließend neue Fälle richtig einordnen.
Unüberwachtes Lernen
Beim unüberwachten Lernen gibt es keine vorgegebenen Labels. Das System sucht selbstständig nach Mustern, Gruppen oder Ausreißern.
Beispiele:
- Kund·innen mit ähnlichem Kaufverhalten gruppieren
- ungewöhnliche Kontobewegungen entdecken
- ähnliche Dokumente clustern
Verstärkendes Lernen
Beim verstärkenden Lernen probiert ein System Handlungen aus und erhält Rückmeldungen in Form von Belohnung oder Bestrafung. Dadurch verbessert es seine Strategie.
Beispiele:
- Ein Spielagent lernt, welche Spielzüge häufiger zum Sieg führen.
- Ein Roboter lernt Bewegungen durch Versuch und Rückmeldung.
- Eine Ampelsteuerung wird auf besseren Verkehrsfluss optimiert.
📝 Übung: Lernart erkennen
Bestimme die passende Lernart und begründe kurz.
- Ein System bekommt 10 000 Fotos, auf denen jeweils „Apfel“, „Birne“ oder „Banane“ vermerkt ist.
- Ein Programm sortiert unbekannte Musikstücke nach Klangähnlichkeit, ohne dass Musikrichtungen vorgegeben sind.
- Eine Spielfigur erhält Pluspunkte, wenn sie ein Ziel erreicht, und Minuspunkte, wenn sie gegen ein Hindernis läuft.
- Eine Lernplattform erkennt anhand bereits bewerteter Aufgaben, ob neue Lösungen vermutlich richtig oder falsch sind.
Lösungshinweis
1 überwachtes Lernen, weil Labels vorhanden sind. 2 unüberwachtes Lernen, weil Gruppen ohne vorgegebene Labels gefunden werden. 3 verstärkendes Lernen, weil Belohnung und Bestrafung genutzt werden. 4 überwachtes Lernen, weil das System aus bereits bewerteten Beispielen lernt.
Klassifikation mit k-nächste-Nachbarn
Der k-nächste-Nachbarn-Algorithmus, kurz k-NN, ist ein Verfahren des überwachten Lernens. Er ordnet einen neuen Datenpunkt einer Klasse zu, indem er die k nächsten bekannten Datenpunkte betrachtet.
Ein Datenpunkt besteht aus Merkmalen. Bei zwei Merkmalen kann man ihn gut als Punkt in einem Koordinatensystem darstellen.
Merke
Ein Label ist die bekannte Klasse eines Trainingsdatensatzes, zum Beispiel „Spam“, „kein Spam“, „viel Nachfrage“ oder „wenig Nachfrage“.
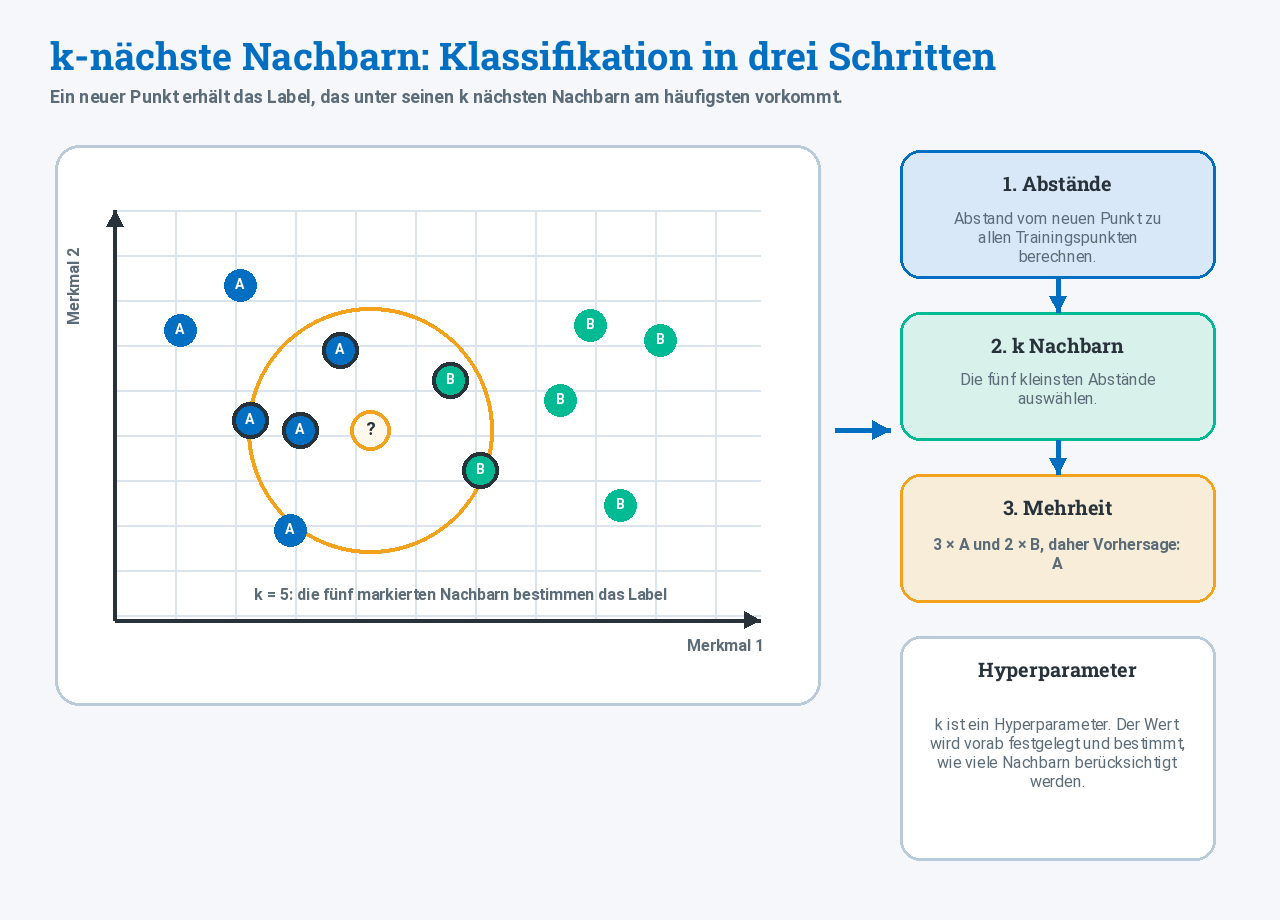
So arbeitet k-NN
- Ein neuer Datenpunkt wird beschrieben, zum Beispiel durch zwei Merkmale.
- Das System berechnet den Abstand zu allen gespeicherten Trainingspunkten.
- Die
knächsten Nachbarn werden ausgewählt. - Das häufigste Label unter diesen Nachbarn wird als Vorhersage verwendet.
Bei k-NN besteht das „Training“ im Wesentlichen darin, die gelabelten Daten zu speichern. Deshalb wird k-NN manchmal als lazy learner bezeichnet: Die eigentliche Arbeit passiert erst bei der Klassifikation neuer Daten.
Die Wahl von k
Der Wert k ist ein Hyperparameter. Er wird nicht automatisch aus einzelnen Trainingsdaten gelernt, sondern vor der Anwendung festgelegt oder über Validierung ausgewählt.
| k-Wert | mögliche Wirkung |
|---|---|
sehr klein, z. B. k = 1 | einzelne Ausreißer können die Entscheidung stark beeinflussen |
| mittlerer sinnvoller Wert | lokale Muster werden berücksichtigt |
| sehr groß | auch weit entfernte, wenig ähnliche Datenpunkte beeinflussen die Entscheidung |
Achtung
Ein zu kleiner k-Wert begünstigt Overfitting. Ein zu großer k-Wert kann zu Underfitting führen.
Abstände und Merkmale
k-NN funktioniert nur sinnvoll, wenn Abstände sinnvoll berechnet werden können. Körpergröße und Temperatur lassen sich als Zahlen gut vergleichen. Lieblingsfarbe oder Wohnbezirk müssen zuerst passend codiert werden. Auch unterschiedliche Größenordnungen können problematisch sein: Ein Einkommen in Euro kann einen Abstand viel stärker beeinflussen als ein Alter in Jahren.
Euklidische Distanz und Manhattan-Distanz
Im Unterricht werden bei k-NN oft zwei einfache Abstandsmaße verglichen:
- Euklidische Distanz: die „Luftlinienentfernung“ zwischen zwei Punkten
- Manhattan-Distanz: die Entfernung entlang horizontaler und vertikaler Schritte, also wie in einem rechtwinkligen Straßennetz
Für zwei Punkte (x₁, y₁) und (x₂, y₂) gilt:
text
Euklidische Distanz:
d = √((x₂ − x₁)² + (y₂ − y₁)²)
Manhattan-Distanz:
d = |x₂ − x₁| + |y₂ − y₁|Je nach Problem kann ein anderes Abstandsmaß sinnvoll sein. In vielen anschaulichen Koordinatensystemen wird die euklidische Distanz verwendet. Die Manhattan-Distanz zeigt aber gut, dass „Nähe“ nicht immer auf genau dieselbe Weise gemessen werden muss.
Merksatz
Ein KI-Modell kann nur so sinnvoll entscheiden, wie seine Daten, Merkmale und Bewertungsregeln es erlauben.
📝 Übung: k-NN für eine Kinovorstellung
Ein Kino möchte abschätzen, ob eine Vorstellung ausverkauft sein wird. Als Merkmale werden die Uhrzeit und der Wochentag verwendet. Die Wochentage sind hier vereinfacht codiert: Montag = 1, Dienstag = 2, …, Sonntag = 7.
| Vorstellung | Uhrzeit | Wochentag | Label |
|---|---|---|---|
| A | 19 | 5 | ausverkauft |
| B | 20 | 6 | ausverkauft |
| C | 22 | 6 | ausverkauft |
| D | 15 | 2 | nicht ausverkauft |
| E | 17 | 3 | nicht ausverkauft |
| F | 21 | 7 | ausverkauft |
| G | 10 | 7 | nicht ausverkauft |
Eine neue Vorstellung findet um 18 Uhr an einem Freitag statt, also bei (18, 5).
- Markiere im Kopf oder auf Papier, welche bekannten Vorstellungen dem neuen Fall wahrscheinlich am ähnlichsten sind.
- Entscheide für
k = 3, ob das Modell eher „ausverkauft“ oder „nicht ausverkauft“ vorhersagen würde. - Erkläre, warum
k = 1empfindlicher gegenüber einzelnen Ausreißern wäre alsk = 3. - Überlege, warum die Codierung von Wochentagen als Zahlen problematisch sein kann.
Lösungshinweis
Für eine mündliche Erklärung reicht zunächst eine begründete Nähe-Einschätzung: Der neue Punkt (18, 5) liegt besonders nahe bei A (19, 5), B (20, 6) und E (17, 3). Damit ergeben sich bei k = 3 zwei Nachbarn mit „ausverkauft“ und ein Nachbar mit „nicht ausverkauft“. Die Vorhersage lautet daher ausverkauft.
Als Zwischenfrage kann man berechnen lassen, wie ein Computersystem diese Nähe bestimmen könnte. Zum Beispiel mit euklidischer Distanz:
text
Abstand zu A:
√((19 − 18)² + (5 − 5)²) = √1 = 1
Abstand zu B:
√((20 − 18)² + (6 − 5)²) = √5 ≈ 2,24
Abstand zu E:
√((17 − 18)² + (3 − 5)²) = √5 ≈ 2,24Mit Manhattan-Distanz würde man die waagrechten und senkrechten Abstände addieren:
text
Abstand zu A: |19 − 18| + |5 − 5| = 1
Abstand zu B: |20 − 18| + |6 − 5| = 3
Abstand zu E: |17 − 18| + |3 − 5| = 3Die Grundidee bleibt: k-NN wählt die nächsten bekannten Fälle und entscheidet nach Mehrheit.
k = 1 wäre empfindlicher, weil ein einzelner naher, aber vielleicht untypischer oder fehlerhafter Datenpunkt die ganze Entscheidung bestimmen könnte. Bei k = 3 wird die Entscheidung etwas stabiler, weil mehrere Nachbarn gemeinsam betrachtet werden.
Die Codierung der Wochentage ist fachlich heikel: Sonntag 7 und Montag 1 liegen rechnerisch weit auseinander, obwohl sie im Wochenrhythmus direkt benachbart sind. Das zeigt, dass nicht nur das Rechenverfahren wichtig ist, sondern auch die sinnvolle Codierung der Merkmale.
Entscheidungsbäume
Ein Entscheidungsbaum klassifiziert Daten, indem er Schritt für Schritt Fragen zu Merkmalen stellt. Jeder innere Knoten enthält eine Entscheidungsregel. Jedes Blatt enthält ein Label.
Ein Entscheidungsbaum kann wissensbasiert von Menschen erstellt werden oder datenbasiert aus gelabelten Trainingsdaten gelernt werden.
Aufbau eines Entscheidungsbaums
| Bestandteil | Bedeutung |
|---|---|
| Wurzel | erste Entscheidungsfrage |
| innerer Knoten | weitere Entscheidungsfrage |
| Kante | Antwort oder Bedingung, die zum nächsten Knoten führt |
| Blatt | endgültiges Label |
Beispiel für eine einfache Regelstruktur:
text
Ist der Boden trocken?
├─ ja: braucht wenig Wasser
└─ nein: steht die Pflanze sonnig?
├─ ja: normal gießen
└─ nein: nicht gießenEntscheidungsbäume lernen
Beim Lernen eines Entscheidungsbaums wird gesucht, welches Merkmal die Daten möglichst gut trennt. Ein gutes Merkmal erzeugt möglichst „reine“ Gruppen, in denen überwiegend dasselbe Label vorkommt.
Der Begriff Informationsgewinn beschreibt, wie hilfreich ein Merkmal für diese Aufteilung ist. Je besser ein Merkmal die Klassen trennt, desto höher ist sein Informationsgewinn.
Einordnung: Wie Entscheidungsbäume Merkmale auswählen
Im Schulbuch wird die Qualität einer Aufteilung über die Unreinheit eines Knotens betrachtet. Ziel ist, möglichst „sortenreine“ Teilmengen zu erzeugen, also Gruppen, in denen überwiegend nur ein Label vorkommt.
Als Hintergrundwissen kann man die Qualität einer Aufteilung mit der Gini-Unreinheit beschreiben. Für zwei Klassen kann sie so notiert werden:
text
Gini = 1 − p₁² − p₂²Dabei steht p₁ für den Anteil der ersten Klasse und p₂ für den Anteil der zweiten Klasse im betrachteten Knoten.
- Gini nahe
0: der Knoten ist sehr rein - Gini hoch: die Klassen sind stärker gemischt
Der Informationsgewinn ergibt sich vereinfacht aus der Frage: Wie stark sinkt die Unreinheit, wenn ich nach einem bestimmten Merkmal aufteile? Das Merkmal mit dem größten Gewinn wird im Entscheidungsbaum bevorzugt.
Für deine Wiederholung ist vor allem wichtig, dass du die Idee dahinter erklären kannst: Ein guter Split erzeugt möglichst reine Teilgruppen.
Hyperparameter bei Entscheidungsbäumen
Auch Entscheidungsbäume haben Hyperparameter. Ein wichtiger Hyperparameter ist die maximale Baumtiefe.
- Ist der Baum zu flach, erkennt er wichtige Muster nicht: Underfitting.
- Ist der Baum zu tief, merkt er sich Zufälle der Trainingsdaten: Overfitting.
Merke
Entscheidungsbäume sind oft besser erklärbar als viele neuronale Netze. Trotzdem können auch sie problematische Entscheidungen treffen, wenn Daten oder Merkmale verzerrt sind.
📝 Übung: Entscheidungsbaum für eine Lernplattform
Eine Lernplattform soll einschätzen, ob Schüler·innen zu einem Thema eine zusätzliche Wiederholung empfohlen bekommen. Die Trainingsdaten enthalten drei Merkmale und ein Label.
| Fall | Fehlerquote hoch? | lange nicht geübt? | Thema schwierig? | Wiederholung empfehlen? |
|---|---|---|---|---|
| L1 | ja | ja | ja | ja |
| L2 | ja | nein | ja | ja |
| L3 | ja | ja | nein | ja |
| L4 | ja | nein | nein | ja |
| L5 | nein | ja | ja | ja |
| L6 | nein | ja | nein | nein |
| L7 | nein | nein | ja | nein |
| L8 | nein | nein | nein | nein |
- Untersuche, welches Merkmal sich als erste Frage im Entscheidungsbaum besonders gut eignet.
- Skizziere einen möglichst einfachen Entscheidungsbaum.
- Entscheide mit deinem Baum für einen neuen Fall:
- Fehlerquote hoch?
nein - lange nicht geübt?
ja - Thema schwierig?
ja
- Fehlerquote hoch?
- Erkläre, warum ein sehr tiefer Baum bei wenigen Trainingsdaten problematisch sein kann.
Lösungshinweis
Didaktisch naheliegend ist zuerst eine qualitative Betrachtung: Das Merkmal Fehlerquote hoch? trennt die Daten bereits sehr gut.
- Wenn
Fehlerquote hoch? = ja, lautet das Label in allen vier Fällenja. - Wenn
Fehlerquote hoch? = nein, muss weiter unterschieden werden.
Ein passender Baum ist daher:
text
Fehlerquote hoch?
├─ ja: Wiederholung empfehlen = ja
└─ nein: lange nicht geübt?
├─ nein: Wiederholung empfehlen = nein
└─ ja: Thema schwierig?
├─ ja: Wiederholung empfehlen = ja
└─ nein: Wiederholung empfehlen = neinFür den neuen Fall gilt: Fehlerquote hoch = nein, lange nicht geübt = ja, Thema schwierig = ja. Der Baum landet daher bei Wiederholung empfehlen = ja.
Als Vertiefung kann man die Qualität der ersten Aufteilung auch mit Gini-Unreinheit begründen. In der gesamten Tabelle gibt es fünf Mal ja und drei Mal nein.
text
Gini(gesamt) = 1 − (5/8)² − (3/8)²
= 1 − 25/64 − 9/64
= 30/64
≈ 0,469Für Fehlerquote hoch? gilt:
text
Fehlerquote hoch = ja:
4 ja, 0 nein → Gini = 0
Fehlerquote hoch = nein:
1 ja, 3 nein
Gini = 1 − (1/4)² − (3/4)²
= 1 − 1/16 − 9/16
= 6/16
= 0,375
gewichtete Unreinheit:
(4/8) · 0 + (4/8) · 0,375 = 0,1875Diese Aufteilung senkt die Unreinheit deutlich. Deshalb ist Fehlerquote hoch? als erste Frage sinnvoll.
Ein sehr tiefer Baum kann bei wenigen Daten problematisch sein, weil er Zufälle der Trainingsdaten auswendig lernt. Dann passt er zwar gut zu diesen Beispielen, entscheidet aber bei neuen Fällen möglicherweise schlecht. Das ist Overfitting.
Training, Validierung, Testen und Modellgüte
Beim überwachten Lernen reicht es nicht, dass ein Modell die Trainingsdaten gut klassifiziert. Entscheidend ist, ob es auch mit neuen, bisher unbekannten Daten sinnvoll umgehen kann.
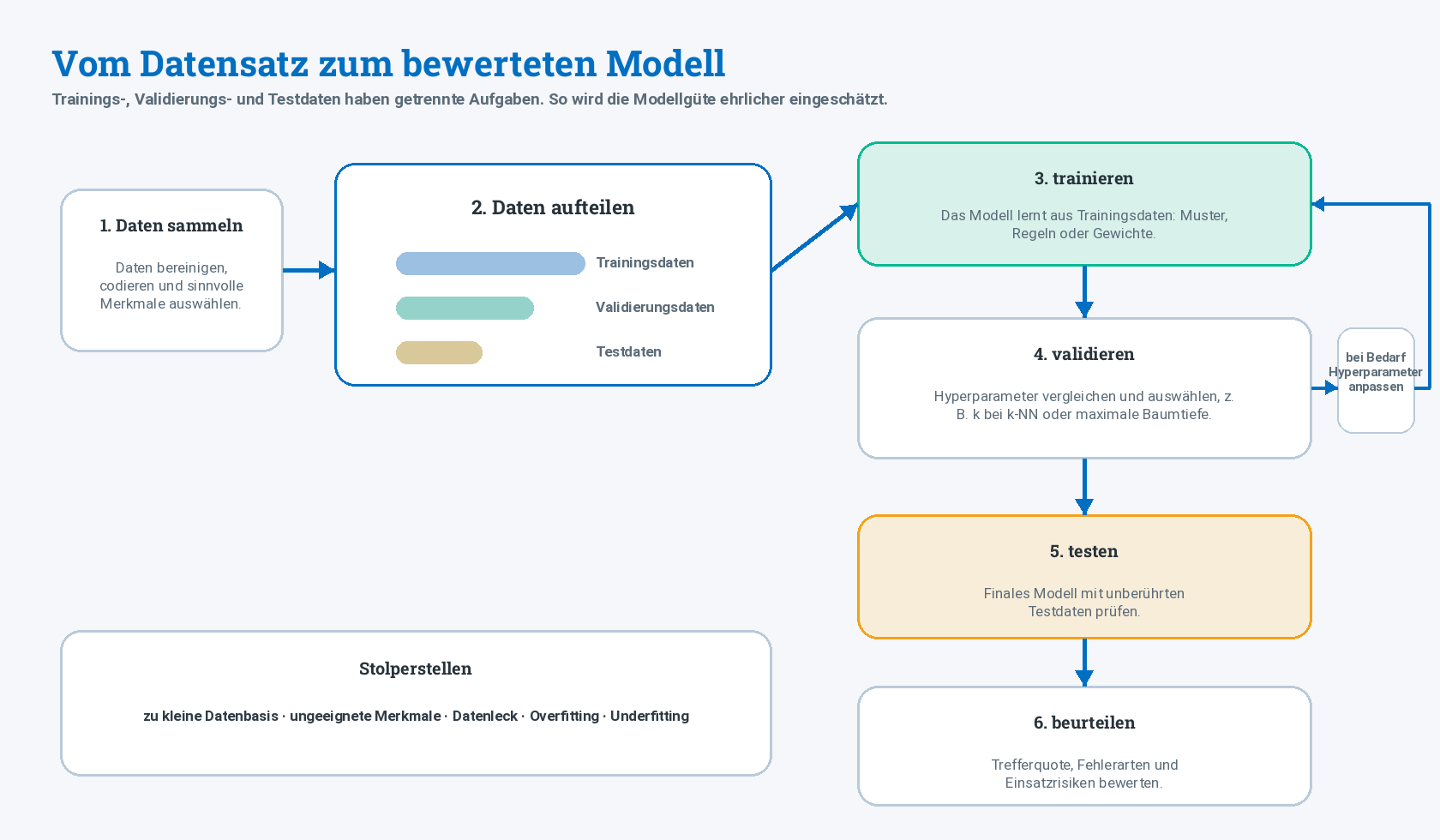
Einordnung: Daten aufteilen
| Datenteil | Aufgabe |
|---|---|
| Trainingsdaten | Das Modell lernt daraus. |
| Validierungsdaten | Hyperparameter werden verglichen und ausgewählt. |
| Testdaten | Erst am Ende wird geprüft, wie gut das finale Modell mit unbekannten Daten umgeht. |
Wichtig
Testdaten dürfen nicht schon während des Trainings oder der Hyperparameter-Auswahl verwendet werden. Sonst wirkt das Modell besser, als es in der Praxis ist.
Einordnung: Overfitting und Underfitting
Overfitting bedeutet Überanpassung. Das Modell passt sich zu stark an einzelne Trainingsdaten an und verallgemeinert schlecht.
Underfitting bedeutet Unteranpassung. Das Modell ist zu grob oder nutzt zu wenig passende Merkmale und erkennt wichtige Muster nicht.
| Problem | typische Ursache | Beispiel |
|---|---|---|
| Overfitting | zu komplexes Modell, zu kleines k, zu tiefer Baum | Modell merkt sich Zufälle der Trainingsdaten |
| Underfitting | zu einfaches Modell, zu großes k, zu wenig Merkmale | Modell erkennt echte Unterschiede nicht |
📝 Übung: Overfitting oder Underfitting?
Ordne zu und begründe.
- Ein Spamfilter erkennt alle Trainingsmails korrekt, stuft aber neue Mails mit dem Wort „gratis“ fast immer als Spam ein.
- Ein Modell für Sportempfehlungen nutzt nur das Merkmal „Alter“ und ignoriert Fitnessziel, Verletzungen und Zeitbudget.
- Ein Entscheidungsbaum verwendet am Ende die Frage, ob eine User-ID mit einer geraden Zahl endet.
- k-NN wird mit
k = 200genutzt, obwohl der Trainingsdatensatz nur 220 sehr unterschiedlich verteilte Punkte enthält.
Lösungshinweis
1 eher Overfitting oder ein ungeeignetes Merkmal, weil das System eine zu spezielle Regel gelernt hat. 2 Underfitting, weil zu wenige aussagekräftige Merkmale genutzt werden. 3 Overfitting, weil ein zufälliges, nicht fachlich begründetes Merkmal verwendet wird. 4 Underfitting, weil sehr viele auch unähnliche Nachbarn einbezogen werden.
Künstliche Neuronen und neuronale Netze
Ein künstliches Neuron ist ein stark vereinfachtes Modell einer Nervenzelle. Es verarbeitet Eingabewerte, gewichtet sie und gibt abhängig von einem Schwellenwert eine Ausgabe zurück.
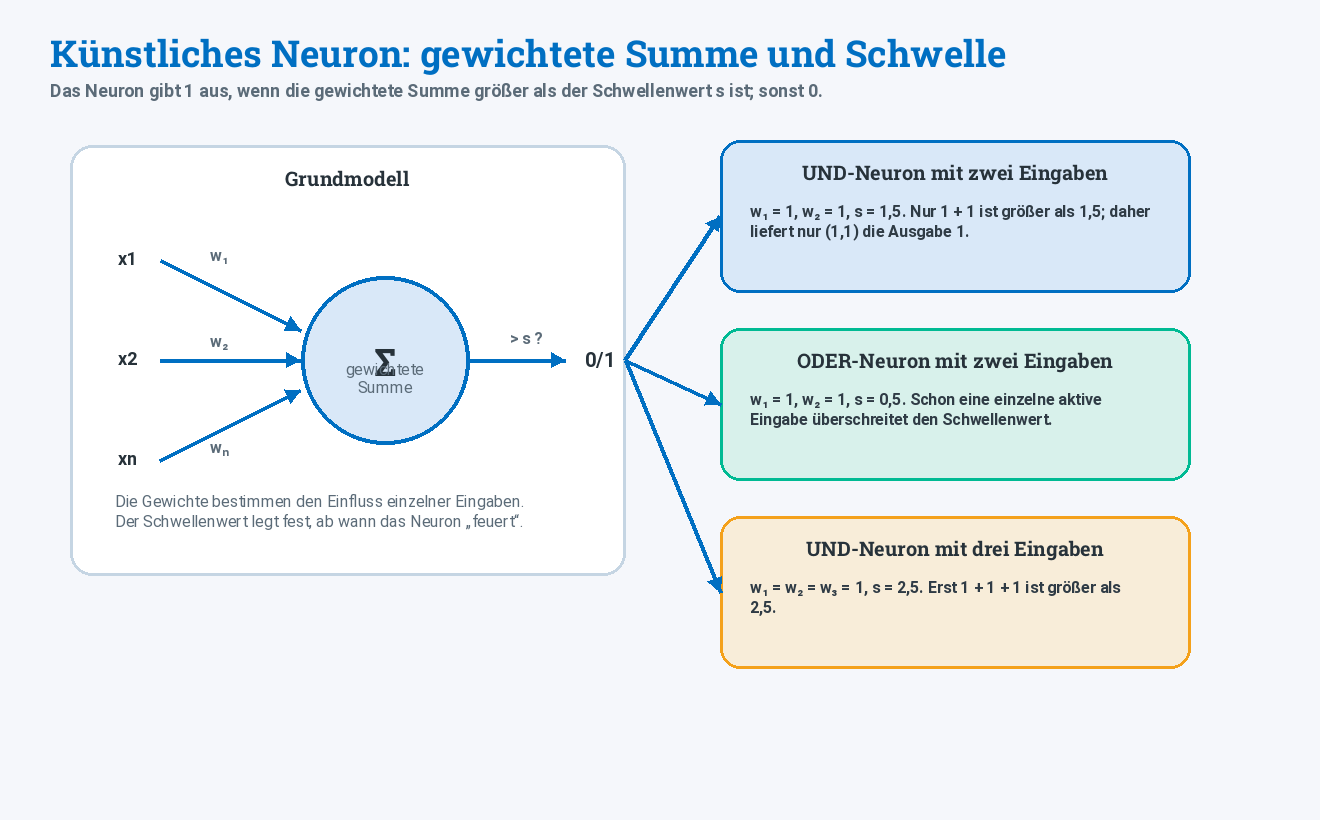
Grundidee
Ein künstliches Neuron berechnet vereinfacht:
text
gewichtete Summe = x₁ · w₁ + x₂ · w₂ + ... + xₙ · wₙDann wird geprüft, ob diese Summe den Schwellenwert überschreitet.
text
wenn gewichtete Summe > Schwellenwert: Ausgabe 1
sonst: Ausgabe 0Die Gewichte bestimmen, wie stark ein Eingabewert das Ergebnis beeinflusst. Der Schwellenwert bestimmt, ab wann das Neuron „feuert“.
Logische Verknüpfungen mit Neuronen
Mit passenden Gewichten und Schwellenwerten lassen sich einfache logische Verknüpfungen modellieren.
| Verknüpfung | mögliche Idee |
|---|---|
| UND | Ausgabe 1 nur, wenn alle relevanten Eingaben aktiv sind. |
| ODER | Ausgabe 1, wenn mindestens eine relevante Eingabe aktiv ist. |
Ein einzelnes künstliches Neuron kann aber nicht beliebig komplexe Probleme lösen. Es trennt Daten im einfachen zweidimensionalen Fall durch eine Gerade. Probleme, die nicht durch eine solche Grenze trennbar sind, brauchen komplexere Strukturen.
Neuronale Netze
Ein neuronales Netz besteht aus mehreren Schichten künstlicher Neuronen:
- Eingabeschicht: nimmt Merkmale auf, zum Beispiel Pixelwerte eines Bildes.
- Verdeckte Schichten: verarbeiten und kombinieren Merkmale.
- Ausgabeschicht: liefert eine Klassifikation oder Vorhersage.
Je mehr Schichten und Neuronen ein Netz hat, desto komplexere Muster kann es lernen. Gleichzeitig wird es schwieriger nachzuvollziehen, warum eine bestimmte Entscheidung getroffen wurde.
Achtung
„Das System hat es gelernt“ bedeutet nicht automatisch, dass die Entscheidung richtig, fair oder erklärbar ist.
📝 Übung: Alarm-Neuron
Ein einfaches Sicherheitssystem hat zwei Eingaben:
x₁ = 1, wenn eine Tür geöffnet wird, sonst0x₂ = 1, wenn Bewegung erkannt wird, sonst0
Das System soll nur Alarm auslösen, wenn beide Bedingungen erfüllt sind.
- Wähle Gewichte und einen Schwellenwert für ein UND-Neuron.
- Prüfe die vier Eingaben
(0,0),(1,0),(0,1),(1,1). - Verändere nur den Schwellenwert so, dass daraus ein ODER-Neuron wird.
Lösungshinweis
Für UND funktioniert zum Beispiel w₁ = 1, w₂ = 1, s = 1,5. Nur 1 + 1 > 1,5 liefert Ausgabe 1. Für ODER kann man bei gleichen Gewichten etwa s = 0,5 wählen. Dann reicht eine einzelne aktive Eingabe.
Chancen, Risiken und Verantwortung
KI-Systeme können Aufgaben automatisieren, Muster sichtbar machen und Menschen unterstützen. Sie können aber auch Fehler verstärken, Vorurteile übernehmen oder Entscheidungen undurchsichtig machen.
Chancen
- große Datenmengen schneller auswerten
- medizinische Bilder oder technische Messdaten vorsortieren
- Barrieren abbauen, etwa durch Übersetzung oder Spracherkennung
- Verkehrsflüsse, Energieverbrauch oder Produktionsprozesse optimieren
- Lernangebote individueller gestalten
Risiken
- fehlerhafte oder verzerrte Trainingsdaten führen zu unfairen Entscheidungen
- Blackbox-Modelle sind schwer nachvollziehbar
- automatisierte Entscheidungen können Menschen benachteiligen
- Datenschutz und Privatsphäre können gefährdet sein
- hoher Ressourcenverbrauch kann ökologische Folgen haben
- Nutzer·innen können Systemen zu stark vertrauen
Leitfrage
Wer trägt Verantwortung, wenn ein KI-System eine Entscheidung vorbereitet oder trifft: Entwickler·innen, Betreiber·innen, Nutzer·innen oder die Institution, die das System einsetzt?
Eine sinnvolle Antwort lautet selten „die KI“. KI-Systeme sind Werkzeuge. Menschen entscheiden, welche Daten gesammelt werden, welche Ziele optimiert werden, wo ein System eingesetzt wird und wie mit Fehlern umgegangen wird.
Erklärbarkeit und Blackbox
Ein Entscheidungsbaum ist häufig gut erklärbar: Man kann den Weg von der Wurzel bis zum Blatt nachvollziehen. Ein großes neuronales Netz kann dagegen sehr leistungsfähig sein, aber seine Entscheidung ist oft schwer verständlich.
In sensiblen Bereichen ist Erklärbarkeit besonders wichtig:
- medizinische Diagnostik
- Bewerbungs- und Auswahlverfahren
- Kreditvergabe
- Schul- und Lernanalysen
- polizeiliche oder sicherheitsrelevante Systeme
Wichtig
Je stärker eine KI-Entscheidung das Leben von Menschen beeinflusst, desto höher müssen Anforderungen an Datenqualität, Transparenz, Kontrolle, Fairness und Widerspruchsmöglichkeiten sein.
📝 Übung: KI in der Schule beurteilen
Eine Lernplattform schlägt automatisch vor, welche Schüler·innen zusätzliche Förderung erhalten sollen. Sie nutzt dafür Noten, Abgabeverhalten und Ergebnisse kurzer Online-Tests.
Beurteile das System anhand folgender Fragen:
- Welche Chancen bietet die Plattform?
- Welche Daten könnten problematisch oder unvollständig sein?
- Welche Fehler könnten entstehen?
- Wer sollte die endgültige Entscheidung treffen?
- Welche Regeln müsste die Schule festlegen, bevor das System eingesetzt wird?
Lösungshinweis
Chancen: frühe Hinweise, Entlastung, gezielte Förderung. Probleme: Noten bilden Lernstand nur teilweise ab, Abgabeverhalten kann von Krankheit, Technik oder familiären Umständen beeinflusst sein. Fehler: falsche Einstufung, Stigmatisierung, übersehene Schüler·innen. Die endgültige Entscheidung sollte nicht allein automatisiert erfolgen. Wichtig wären Transparenz, Datenschutz, menschliche Kontrolle, Einspruchsmöglichkeit und regelmäßige Überprüfung der Modellgüte.
Prüfungsvorbereitung
Ich kann …
- KI als Sammelbegriff erklären und Beispiele aus dem Alltag einordnen.
- schwache und starke KI unterscheiden.
- den Turing-Test beschreiben und seine Grenzen beurteilen.
- wissensbasierte und datenbasierte Systeme vergleichen.
- überwachtes, unüberwachtes und verstärkendes Lernen unterscheiden.
- k-NN Schritt für Schritt erklären und auf einfache Punktdaten anwenden.
- den Einfluss von
k, Merkmalen und Abständen auf k-NN beurteilen. - Entscheidungsbäume lesen, erstellen und hinsichtlich ihrer Erklärbarkeit bewerten.
- Hyperparameter an Beispielen erklären.
- die Grundidee eines künstlichen Neurons mit Gewichten und Schwellenwert erklären.
- einfache UND- und ODER-Neuronen nachvollziehen.
- Chancen und Risiken von KI-Systemen differenziert diskutieren.
- Verantwortung bei automatisierten Entscheidungen begründen.
Mini-Check
- Warum sind heutige KI-Systeme meist schwache KI?
- Was wäre mit starker KI gemeint?
- Was überprüft der Turing-Test?
- Warum beweist ein bestandener Turing-Test nicht sicher, dass ein System wirklich „versteht“?
- Was ist der Unterschied zwischen wissensbasierter und datenbasierter KI?
- Ordne k-NN einer Lernart zu und begründe.
- Nenne je ein Beispiel für überwachtes, unüberwachtes und verstärkendes Lernen.
- Was passiert bei k-NN, wenn
ksehr klein gewählt wird? - Warum können Merkmalsauswahl und Abstandsmaß bei k-NN die Entscheidung verändern?
- Was ist ein Hyperparameter? Nenne zwei Beispiele.
- Was ist ein Blatt in einem Entscheidungsbaum?
- Warum kann ein zu tiefer Entscheidungsbaum problematisch sein?
- Welche Rolle spielt der Schwellenwert bei einem künstlichen Neuron?
- Warum ist Erklärbarkeit bei KI-Systemen gesellschaftlich wichtig?
Kurzlösungen
1 Heutige KI-Systeme sind meist auf bestimmte Aufgaben spezialisiert, zum Beispiel Bilderkennung, Textgenerierung oder Empfehlungssysteme. Sie besitzen keine allgemeine menschenähnliche Intelligenz.
2 Starke KI würde flexibel und allgemein denken, lernen und Probleme in vielen unterschiedlichen Bereichen lösen können. Solche Systeme gibt es derzeit nicht im menschlich-allgemeinen Sinn.
3 Der Turing-Test prüft, ob ein Mensch in einem schriftlichen Dialog zuverlässig unterscheiden kann, ob er mit einem Menschen oder einer Maschine kommuniziert.
4 Ein System kann überzeugend antworten, ohne Begriffe, Weltwissen oder Bedeutung so zu verstehen wie ein Mensch. Der Test bewertet Verhalten im Dialog, nicht inneres Verstehen.
5 Wissensbasierte Systeme nutzen explizit formulierte Regeln; datenbasierte Systeme leiten Muster aus Daten ab.
6 k-NN gehört zum überwachten Lernen, weil bekannte Trainingsdaten mit Labels verwendet werden. Ein neuer Punkt wird anhand ähnlicher gelabelter Beispiele klassifiziert.
7 Überwacht: Spam/kein Spam anhand gelabelter E-Mails. Unüberwacht: Kund·innengruppen ohne vorgegebene Labels finden. Verstärkend: ein Spielsystem lernt durch Belohnung und Bestrafung.
8 Einzelne Ausreißer oder fehlerhafte Datenpunkte können die Entscheidung stark beeinflussen; Overfitting wird wahrscheinlicher.
9 k-NN entscheidet nach Nähe. Andere Merkmale, ungünstige Skalierungen oder ein anderes Abstandsmaß können verändern, welche Nachbarn als „nah“ gelten.
10 Ein Hyperparameter ist ein Einstellwert, der vor dem Lernen festgelegt oder über Validierung ausgewählt wird. Beispiele: k bei k-NN und maximale Baumtiefe bei Entscheidungsbäumen.
11 Ein Blatt ist ein Endknoten, der das vorhergesagte Label enthält.
12 Ein sehr tiefer Baum kann Zufälle der Trainingsdaten auswendig lernen und bei neuen Fällen schlechter entscheiden. Das nennt man Überanpassung.
13 Der Schwellenwert legt fest, ab welcher gewichteten Summe das Neuron die Ausgabe 1 liefert.
14 Entscheidungen müssen nachvollziehbar, überprüfbar und anfechtbar sein, besonders wenn Menschen betroffen sind, etwa bei Medizin, Schule, Bewerbung oder Kreditvergabe.