Appearance
🧠 Thema 1: Computational Thinking, Digitalisierung und mathematisch-logische Grundlagen
Überblick
In diesem Themenbereich geht es um zwei Grundideen der Informatik:
Wie denkt man informatisch?
Also: Wie kann man Probleme so strukturieren, dass sie systematisch gelöst werden können?Wie werden Informationen digital dargestellt?
Also: Wie werden Zahlen, Texte, Bilder oder Videos so codiert, dass ein Computer sie speichern, verarbeiten und übertragen kann?
Leitfrage
Wie lassen sich Probleme, Informationen und Abläufe so darstellen, dass Menschen sie verstehen und Computer sie verarbeiten können?
Computational Thinking
Computational Thinking bedeutet nicht einfach „wie ein Computer denken“. Gemeint ist vielmehr eine Denkweise, mit der Probleme so zerlegt, geordnet und beschrieben werden, dass sie schrittweise lösbar werden.
Diese Denkweise ist in der Informatik zentral, hilft aber auch außerhalb der Informatik: beim Planen, Sortieren, Vergleichen, Strukturieren, Modellieren und Begründen.
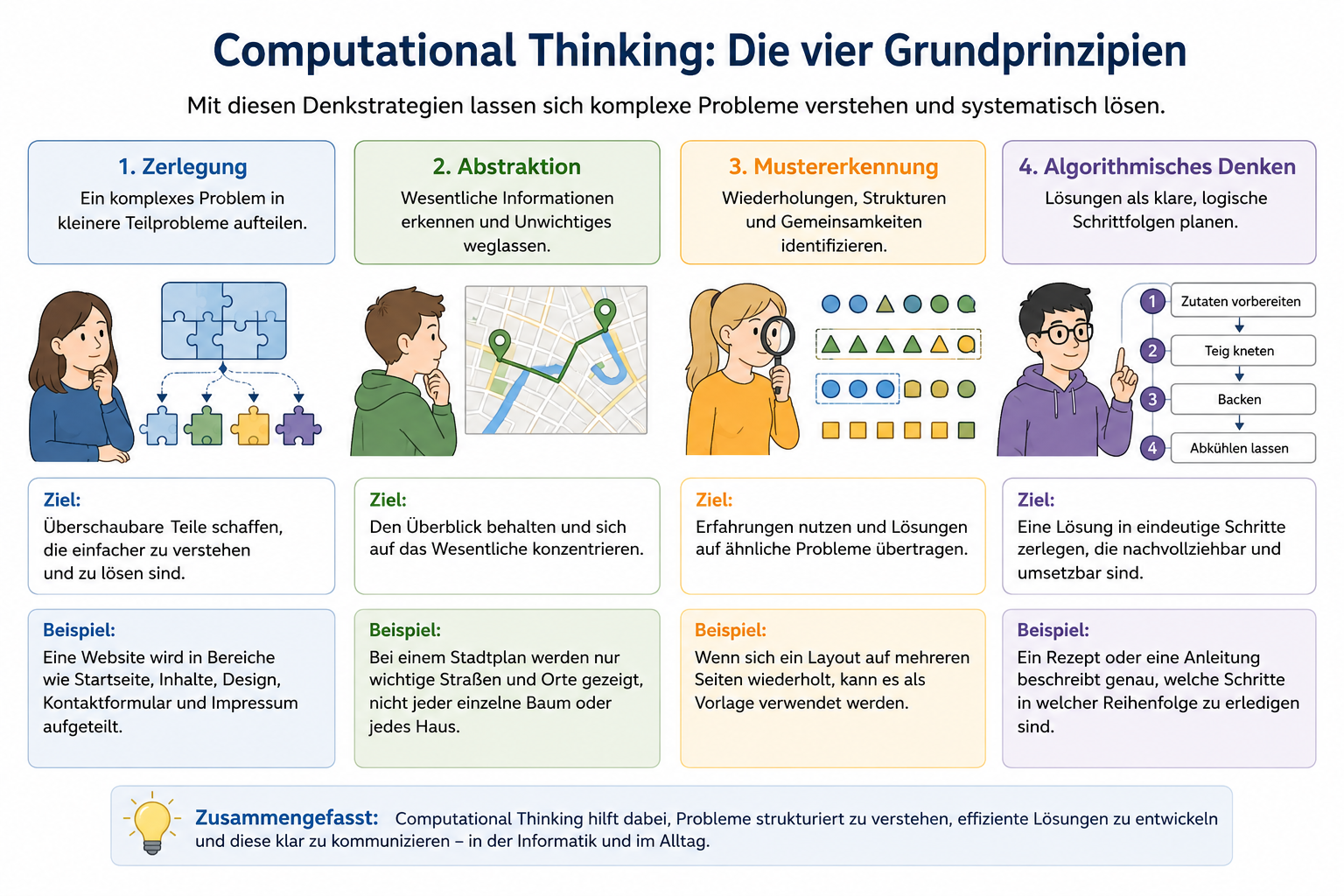
Die vier Grundprinzipien
Zerlegung
Ein großes Problem wird in kleinere Teilprobleme aufgeteilt.
Beispiel:
Du willst eine Website erstellen. Statt „Website machen“ als riesige Aufgabe zu sehen, zerlegst du sie in Teilaufgaben:
- Startseite planen
- Texte schreiben
- Bilder auswählen
- HTML-Struktur erstellen
- CSS-Design festlegen
- Seite testen
Mustererkennung
Man sucht nach Ähnlichkeiten, Wiederholungen oder bekannten Strukturen.
Beispiel:
Wenn mehrere Webseiten immer aus Überschrift, Bild, Text und Link bestehen, kannst du dieses Muster erkennen und für neue Seiten wiederverwenden.
Abstraktion
Unwichtige Details werden ausgeblendet. Übrig bleibt das Wesentliche.
Beispiel:
Bei einem Stadtplan ist nicht jeder Baum eingezeichnet. Wichtig sind Straßen, Haltestellen, Wege und Orientierungspunkte. Der Plan ist also eine vereinfachte Darstellung der Wirklichkeit.
Algorithmisches Denken
Eine Lösung wird als klare Schrittfolge formuliert.
Beispiel:
Ein Kochrezept, eine Bauanleitung oder ein Programm bestehen aus Anweisungen in einer bestimmten Reihenfolge. Wenn die Schritte eindeutig genug sind, kann jemand anderes sie nachvollziehen.
Merke
Computational Thinking verbindet genaues Denken mit verständlicher Darstellung. Es geht darum, Probleme so zu beschreiben, dass daraus ein nachvollziehbarer Lösungsweg entstehen kann.
Von der Idee zum Algorithmus
Ein Algorithmus ist eine eindeutige Schrittfolge zur Lösung eines Problems. Nicht jede Anleitung ist automatisch ein guter Algorithmus. Gute algorithmische Beschreibungen sind möglichst klar, vollständig und überprüfbar.
Ungenau:
Geh irgendwie Richtung Schule und dann links.
Genauer:
Gehe 200 Meter geradeaus. Biege bei der Ampel links ab. Folge der Straße bis zum Haupteingang.
Für Menschen reicht oft eine ungenaue Beschreibung, weil sie Zusammenhänge erkennen können. Computer brauchen wesentlich eindeutigere Anweisungen.
📝 Übung: Alltag algorithmisch beschreiben
Wähle eine Alltagshandlung und beschreibe sie als Algorithmus:
- ein Passwort ändern
- eine Datei sinnvoll benennen und speichern
- eine Nachricht mit Anhang versenden
- eine einfache Zeichnung Schritt für Schritt erstellen
Achte darauf, dass deine Anleitung eindeutig, geordnet und vollständig ist.
Lösungshinweis
Beispiel: Datei sinnvoll speichern
- Öffne das Dokument.
- Klicke auf „Speichern unter“.
- Wähle den passenden Ordner aus.
- Gib einen Dateinamen nach dem Muster
fach_thema_name_datumein. - Wähle das passende Dateiformat.
- Klicke auf „Speichern“.
- Kontrolliere, ob die Datei im richtigen Ordner liegt.
Modelle, Skizzen und Codierung
In der Informatik werden Probleme oft durch Modelle dargestellt. Ein Modell ist eine vereinfachte Darstellung eines Ausschnitts der Wirklichkeit.
Beispiele für Modelle:
- Ablaufdiagramm
- Zustandsdiagramm
- Tabelle
- Netzplan
- ER-Modell
- Skizze einer Benutzeroberfläche
- Pseudocode
Ein Modell ist nie die Wirklichkeit selbst. Es hebt bestimmte Aspekte hervor und lässt andere weg.
Wichtig
Ein Bauplan für Menschen und ein Programm für Computer sind nicht dasselbe.
Menschen können vernetzt denken: Sie erkennen Zusammenhänge, ergänzen fehlende Informationen aus Erfahrung, deuten Skizzen flexibel und können bei Unklarheiten nachfragen.
Computer arbeiten dagegen streng nach den vorgegebenen Anweisungen. Ein Programm muss daher wesentlich genauer codiert sein als eine Skizze oder Bauanleitung für Menschen.
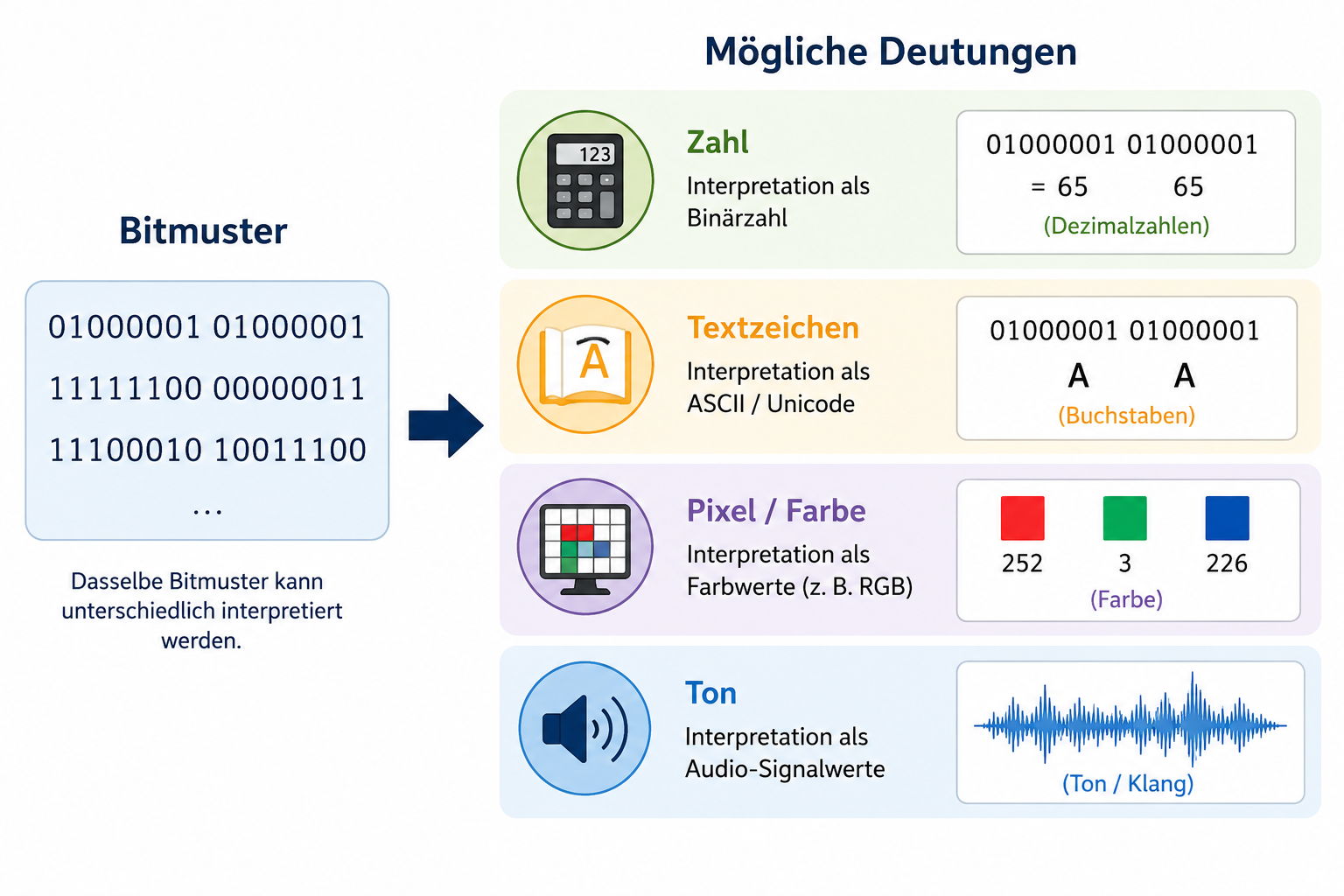
Digitale Informationsverarbeitung
Computer speichern und verarbeiten Daten in Form von Bits. Ein Bit kann zwei Zustände darstellen:
- 0 oder 1
- aus oder ein
- falsch oder wahr
- kein Signal oder Signal
Mehrere Bits ergeben ein Bitmuster. Erst durch eine passende Interpretation wird daraus Information.
Dasselbe Bitmuster kann je nach Kontext unterschiedlich gedeutet werden:
- als Zahl
- als Buchstabe
- als Farbe
- als Teil eines Bildes
- als Toninformation
- als Maschinenbefehl
Merke
Daten sind gespeicherte Zeichen oder Signale. Information entsteht erst, wenn diese Daten sinnvoll interpretiert werden.
Symbolische Darstellung
Digitale Codes sind symbolisch. Das bedeutet: Die Nullen und Einsen sind nicht „die Sache selbst“, sondern stehen stellvertretend für etwas.
Beispiele:
- Die Bitfolge
01000001kann im passenden Zeichencode für den BuchstabenAstehen. - Ein RGB-Wert kann eine Farbe beschreiben.
- Eine Folge von Zahlenwerten kann Tonhöhen oder Lautstärken in einer Audiodatei darstellen.
- Viele Bildpunkte mit Farbwerten ergeben gemeinsam ein digitales Bild.
Ein Computer muss daher wissen, wie ein Bitmuster zu lesen ist. Dabei helfen unter anderem:
- Dateiformate
- Metadaten
- Programme
- Betriebssysteme
- Standards wie Unicode, JPEG, PNG, MP3 oder MP4
Binärzahlen und Zweierpotenzen
Menschen rechnen im Alltag meistens im Dezimalsystem. Dieses verwendet zehn Ziffern:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
Computer arbeiten technisch mit zwei Zuständen. Deshalb ist das Binärsystem besonders geeignet. Es verwendet nur:
0 und 1
Die Stellenwerte im Binärsystem sind Zweierpotenzen:
| Binärstelle von rechts | Zweierpotenz | Dezimalwert |
|---|---|---|
| 1. Stelle | 2⁰ | 1 |
| 2. Stelle | 2¹ | 2 |
| 3. Stelle | 2² | 4 |
| 4. Stelle | 2³ | 8 |
| 5. Stelle | 2⁴ | 16 |
| 6. Stelle | 2⁵ | 32 |
| 7. Stelle | 2⁶ | 64 |
| 8. Stelle | 2⁷ | 128 |
Merksatz
Im Binärsystem verdoppelt sich der Stellenwert bei jeder Stelle nach links. Deshalb spricht man von Zweierpotenzen.
Beispiel:
1011₂
Das bedeutet:
| Binärziffer | Stellenwert | Wird gezählt? |
|---|---|---|
| 1 | 8 | ja |
| 0 | 4 | nein |
| 1 | 2 | ja |
| 1 | 1 | ja |
Also:
8 + 2 + 1 = 11
Daher gilt:
1011₂ = 11₁₀
📝 Übung: Binärzahlen lesen
Wandle die folgenden Binärzahlen in Dezimalzahlen um:
101₂1001₂1111₂10000₂11010₂
Lösung
101₂ = 5₁₀1001₂ = 9₁₀1111₂ = 15₁₀10000₂ = 16₁₀11010₂ = 26₁₀
📝 Übung: Dezimalzahlen binär darstellen
Stelle die folgenden Dezimalzahlen im Binärsystem dar:
613182532
Lösung
6₁₀ = 110₂13₁₀ = 1101₂18₁₀ = 10010₂25₁₀ = 11001₂32₁₀ = 100000₂
📝 Übung: Zweierpotenzen erklären
Warum kommen in der Binärdarstellung genau die Werte 1, 2, 4, 8, 16, 32, ... vor?
Lösungshinweis
Diese Werte sind Zweierpotenzen:
- 1 = 2⁰
- 2 = 2¹
- 4 = 2²
- 8 = 2³
- 16 = 2⁴
- 32 = 2⁵
Jede Stelle kann entweder verwendet werden (1) oder nicht verwendet werden (0). Dadurch lassen sich Zahlen eindeutig zusammensetzen.
Warum Computer binär arbeiten
Computer verwenden binäre Zustände nicht, weil Menschen das besonders angenehm finden, sondern weil es technisch zuverlässig ist.
Elektronische Bauteile können zwei Zustände besonders robust unterscheiden:
- Spannung liegt an / liegt nicht an
- Strom fließt / fließt nicht
- magnetisiert / nicht magnetisiert
- Lichtimpuls / kein Lichtimpuls
Zwei klar unterscheidbare Zustände sind weniger fehleranfällig als viele feine Abstufungen.
Kurz gesagt
Binärdarstellung ist technisch einfach, robust und gut mit elektronischer Hardware vereinbar.
Dateigrößen und Datenmengen
Digitale Daten benötigen Speicherplatz. Typische Einheiten sind:
| Einheit | Bedeutung |
|---|---|
| 1 Bit | kleinste Informationseinheit |
| 1 Byte | 8 Bit |
| 1 KB | ungefähr 1.000 Byte |
| 1 MB | ungefähr 1.000 KB |
| 1 GB | ungefähr 1.000 MB |
| 1 TB | ungefähr 1.000 GB |
Typische Größenordnungen:
| Datei | Mögliche Größe |
|---|---|
| einfache Textdatei | wenige KB |
| Foto | einige MB |
| Lied | einige MB |
| kurzes Video | einige 10 bis 100 MB |
| Film in hoher Qualität | mehrere GB |
Die genaue Größe hängt vom Format, von der Auflösung, von der Länge und von der Kompression ab.
Kompression
Datenkompression bedeutet, Daten platzsparender darzustellen. Das ist wichtig, weil digitale Systeme große Datenmengen speichern und übertragen müssen.
Beispiele:
- Streamingdienste übertragen Videos komprimiert.
- Fotos werden oft als JPEG gespeichert.
- ZIP-Dateien bündeln und verkleinern Dateien.
- Messenger reduzieren manchmal Bild- oder Videogröße.
Verlustfreie und verlustbehaftete Kompression
Verlustfreie Kompression
Die ursprünglichen Daten können vollständig wiederhergestellt werden.
Sinnvoll bei:
- Textdateien
- Programmen
- Tabellen
- medizinischen oder wissenschaftlichen Daten
- ZIP-Archiven
Verlustbehaftete Kompression
Ein Teil der Information wird entfernt. Die Datei wird kleiner, aber das Original kann nicht vollständig rekonstruiert werden.
Sinnvoll bei:
- Fotos
- Musik
- Videos
- Streaming
Dabei wird ausgenutzt, dass Menschen kleine Unterschiede oft kaum wahrnehmen.
Wichtig
Bei einem Programm darf kein Bit „ungefähr richtig“ sein. Bei einem stark komprimierten Foto kann ein kleiner Qualitätsverlust dagegen akzeptabel sein.
Lauflängencodierung
Die Lauflängencodierung, kurz RLE, ist ein einfaches verlustfreies Kompressionsverfahren. Sie eignet sich besonders gut, wenn viele gleiche Zeichen direkt hintereinander vorkommen.
Stell dir ein sehr einfaches Schwarz-Weiß-Bild vor:
0steht für weiß1steht für schwarz
Ein Bildausschnitt könnte als Bitfolge so gespeichert sein:
txt
000000111100000011Statt jedes einzelne Bit zu speichern, kann man notieren, wie oft ein Zeichen hintereinander vorkommt:
txt
6×0, 4×1, 6×0, 2×1Das bedeutet:
- sechsmal weiß
- viermal schwarz
- sechsmal weiß
- zweimal schwarz
Bei Bildern mit großen einfarbigen Flächen kann das Speicherplatz sparen. Bei sehr unruhigen Bildern mit vielen Wechseln bringt RLE dagegen wenig.
Wichtig: 6×0 ist noch kein fertiger Binärcode
Die Schreibweise 6×0 ist zunächst nur eine verständliche Kurzschreibweise für Menschen.
Damit ein Computer diese Angabe speichern kann, muss auch die Zahl 6 wieder binär codiert werden.
Wenn man zum Beispiel festlegt, dass jede Lauflänge mit 4 Bit gespeichert wird, dann gilt:
| Dezimalzahl | 4-Bit-Binärcode |
|---|---|
| 2 | 0010 |
| 4 | 0100 |
| 6 | 0110 |
Dann könnte man 6×0 so speichern:
txt
0110 0Das bedeutet:
0110steht für die Lauflänge60steht für die Farbe Weiß
Entsprechend wäre:
txt
4×1 = 0100 1
6×0 = 0110 0
2×1 = 0010 1Eine vollständige technische Codierung der Folge
txt
000000111100000011könnte vereinfacht so aussehen:
txt
0110 0 | 0100 1 | 0110 0 | 0010 1In echten Dateiformaten ist die Speicherung meist komplexer. Das Grundprinzip bleibt aber: Nicht nur die Farbe, sondern auch die Anzahl der Wiederholungen muss eindeutig codiert werden.
Lebensweltbezug
Sehr einfache Schwarz-Weiß-Bilder kann man mit nur 1 Bit pro Bildpunkt darstellen: 0 oder 1.
Moderne Bilder verwenden aber oft 24-Bit-Farbtiefe. Dabei werden für jeden Bildpunkt meist je 8 Bit für Rot, Grün und Blau gespeichert.
Damit sind ungefähr 16,7 Millionen Farben möglich:
256 × 256 × 256 = 16 777 216
Das erklärt, warum Fotos viel mehr Speicherplatz benötigen als einfache Schwarz-Weiß-Grafiken.
📝 Übung: RLE mit Schwarz-Weiß-Bildern
Ein sehr einfaches Schwarz-Weiß-Bild wird zeilenweise als Bitfolge gespeichert.
0 bedeutet weiß, 1 bedeutet schwarz.
Komprimiere folgende Bitfolge mit Lauflängencodierung:
txt
000011111100001111Lösung
Menschlich lesbare Kurzschreibweise:
txt
4×0, 6×1, 4×0, 4×1Die ursprüngliche Folge hat 18 Bits.
Ob dadurch wirklich Speicherplatz gespart wird, hängt davon ab, wie die Lauflängen technisch gespeichert werden.
Wenn jede Lauflänge zum Beispiel mit 4 Bit gespeichert wird, könnte die Codierung so aussehen:
txt
0100 0 | 0110 1 | 0100 0 | 0100 1Dabei steht:
0100für 40110für 6- die einzelne folgende Ziffer für die Farbe
In dieser vereinfachten Form benötigt jeder Block 5 Bit: 4 Bit für die Anzahl und 1 Bit für die Farbe.
Vier Blöcke benötigen also 4 × 5 = 20 Bit.
Das wäre in diesem Mini-Beispiel sogar mehr als die ursprünglichen 18 Bit. RLE lohnt sich also besonders dann, wenn lange Folgen gleicher Werte vorkommen.
📝 Übung: RLE beurteilen
Warum eignet sich RLE für einfache Logos oder Icons oft besser als für Fotos?
Lösungshinweis
Logos, Icons oder einfache Grafiken enthalten häufig größere Flächen mit gleicher Farbe. Dadurch entstehen lange Folgen gleicher Werte.
Fotos enthalten dagegen viele Farbwechsel, Helligkeitsunterschiede und Details. Dadurch wechseln die Werte ständig, und RLE kann kaum sinnvoll verkürzen.
Huffman-Codierung
Die Huffman-Codierung ist ein verlustfreies Kompressionsverfahren. Die Grundidee lautet:
Häufige Zeichen erhalten kurze Codes.
Seltene Zeichen erhalten längere Codes.
Dadurch kann ein Text insgesamt mit weniger Bits gespeichert werden.
Vorgehensweise beim Erstellen eines Huffman-Baums
Im Unterricht verwenden wir dafür folgenden Ablauf:
- Zähle die Häufigkeit der Zeichen.
- Schreibe die Zeichen mit ihren Häufigkeiten als einzelne Knoten in aufsteigender Reihenfolge nach Häufigkeit in die oberste Reihe.
- Verbinde jeweils die zwei Knoten mit der geringsten Häufigkeit.
- Aus diesen beiden Knoten entsteht darunter ein neuer gemeinsamer Knoten mit der addierten Häufigkeit.
- Wiederhole diesen Vorgang, bis unten nur noch ein gemeinsamer Gesamtknoten übrig ist.
- Beschrifte die Kanten konsequent:
- linke Kante:
0 - rechte Kante:
1
- linke Kante:
- Bei gleichem Knotengewicht wird nach der im Unterricht festgelegten Links-Rechts-Ordnung gearbeitet, damit der Baum eindeutig nachvollziehbar bleibt.
- Lies den Code für jedes Zeichen entlang seines Pfades durch den Baum ab.
- Vergleiche anschließend die benötigte Bitanzahl vor und nach der Codierung.
Merke
Huffman-Codierung nutzt Häufigkeiten. Zeichen, die oft vorkommen, sollen möglichst kurze Bitfolgen erhalten. Dadurch wird der gesamte Text kürzer gespeichert.
Beispiel: Huffman-Codierung mit EIERSPEISSE
Wir betrachten das Wort:
txt
EIERSPEISSEZuerst zählen wir die Buchstabenhäufigkeiten:
| Zeichen | Häufigkeit |
|---|---|
| P | 1 |
| R | 1 |
| I | 2 |
| S | 3 |
| E | 4 |
Insgesamt besteht das Wort aus 11 Zeichen.
Die Zeichen werden in aufsteigender Reihenfolge ihrer Häufigkeit notiert:
txt
P(1) R(1) I(2) S(3) E(4)Die Verknüpfung erfolgt schrittweise:
txt
P(1) + R(1) → (2)
(2) + I(2) → (4)
(4) + S(3) → (7)
(7) + E(4) → (11)Eine kompakte Baumdarstellung im Unterrichtsstil:
txt
P(1) R(1) I(2) S(3) E(4)
\0 /1 /1 /1 /1
\ / / / /
(2) / / /
\0 / / /
\ / / /
(4) / /
\0 / /
\ / /
(7) /
\0 /
\ /
(11)Hinweis zur Darstellung
Der ASCII-Baum zeigt vereinfacht, welche Knoten verbunden werden. Die Codes werden entlang der beschrifteten Kanten gelesen:
- linke Kante =
0 - rechte Kante =
1
Bei handschriftlichen Bäumen oder Grafiken kann dieselbe Struktur übersichtlicher dargestellt werden.
Die Codes ergeben sich aus dem Pfad vom Gesamtknoten (11) zum jeweiligen Zeichen:
| Zeichen | Code | Häufigkeit | Benötigte Bits |
|---|---|---|---|
| E | 1 | 4 | 4 × 1 = 4 |
| S | 01 | 3 | 3 × 2 = 6 |
| I | 001 | 2 | 2 × 3 = 6 |
| P | 0000 | 1 | 1 × 4 = 4 |
| R | 0001 | 1 | 1 × 4 = 4 |
Das Wort
txt
EIERSPEISSEwird damit zu:
txt
E I E R S P E I S S E
1 001 1 0001 01 0000 1 001 01 01 1Zusammengeschrieben:
txt
100110001010000100101011Das sind:
txt
4 + 6 + 6 + 4 + 4 = 24 BitVergleich mit fester 8-Bit-Codierung
Als einfache Referenz verwenden wir:
txt
1 Zeichen = 8 Bit = 1 ByteDas Wort EIERSPEISSE hat 11 Zeichen.
txt
11 Zeichen × 8 Bit = 88 BitDie Huffman-Codierung benötigt in diesem Beispiel 24 Bit.
txt
88 Bit - 24 Bit = 64 Bit ErsparnisHinweis
Die 8-Bit-Rechnung ist eine vereinfachte Vergleichsrechnung. Moderne Zeichencodierungen wie UTF-8 können je nach Zeichen unterschiedlich viele Bytes benötigen. Für einfache Großbuchstaben ist die Annahme „1 Zeichen ≈ 1 Byte“ als Modell aber gut nachvollziehbar.
📝 Übung: Huffman-Codierung mit GOMMEMODE
Ein kurzes Wort lautet:
txt
GOMMEMODE- Zähle die Häufigkeit aller Buchstaben.
- Schreibe die Knoten mit Häufigkeiten in aufsteigender Reihenfolge in die oberste Reihe.
- Verbinde jeweils die zwei Knoten mit der geringsten Häufigkeit.
- Beschrifte linke Kanten mit
0und rechte Kanten mit1. - Lies die Codes für alle Buchstaben ab.
- Vergleiche die benötigte Bitanzahl mit einer festen 8-Bit-Codierung.
Lösungshinweis
Das Wort lautet:
txt
GOMMEMODEDie Häufigkeiten sind:
| Zeichen | Häufigkeit |
|---|---|
| D | 1 |
| G | 1 |
| E | 2 |
| O | 2 |
| M | 3 |
Insgesamt besteht das Wort aus 9 Zeichen.
Die Zeichen werden in aufsteigender Reihenfolge ihrer Häufigkeit notiert:
txt
D(1) G(1) E(2) O(2) M(3)Die Verknüpfung erfolgt schrittweise:
txt
D(1) + G(1) → (2)
(2) + E(2) → (4)
O(2) + M(3) → (5)
(4) + (5) → (9)Eine kompakte Baumdarstellung:
txt
D(1) G(1) E(2) O(2) M(3)
\0 /1 /1 \0 /1
\ / / \ /
(2) / (5)
\0 / /1
\ / /
(4) /
\0 /
\ /
\ /
(9)Mögliche Codes:
| Zeichen | Code | Häufigkeit | Benötigte Bits |
|---|---|---|---|
| D | 000 | 1 | 1 × 3 = 3 |
| G | 001 | 1 | 1 × 3 = 3 |
| E | 01 | 2 | 2 × 2 = 4 |
| O | 10 | 2 | 2 × 2 = 4 |
| M | 11 | 3 | 3 × 2 = 6 |
Gesamt:
txt
3 + 3 + 4 + 4 + 6 = 20 BitVergleich mit fester 8-Bit-Codierung:
txt
9 Zeichen × 8 Bit = 72 BitDie Huffman-Codierung benötigt 20 Bit.
txt
72 Bit - 20 Bit = 52 Bit ErsparnisEine mögliche Codierung von GOMMEMODE ist:
txt
G O M M E M O D E
001 10 11 11 01 11 10 000 01Zusammengeschrieben:
txt
0011011110111100001Das sind 20 Bits.
Prüfungsvorbereitung
Die folgenden Aufgaben trainieren dieselben Kompetenzen, verwenden aber andere Kontexte, Daten und Beispiele.
📝 Übung: Computational Thinking im Alltag
Du planst mit drei Freund·innen ein kleines Klassenprojekt: Eine Website soll die besten Lernstrategien in der Abschlussphase sammeln.
- Zerlege das Projekt in sinnvolle Teilaufgaben.
- Nenne Muster, die auf mehreren Unterseiten wiederverwendet werden könnten.
- Erkläre, welche Details du für ein erstes Modell weglassen würdest.
- Formuliere einen einfachen Algorithmus für den Ablauf: „Neuen Lerntipp hinzufügen“.
📝 Übung: Symbolische Codierung
Ein Computer speichert ein Bild nicht als „Bild“, sondern als Daten.
- Erkläre, warum ein digitales Bild aus Zahlen bzw. Bitmustern bestehen kann.
- Beschreibe, welche Rolle Dateiformat und Programm beim Öffnen spielen.
- Begründe, warum dasselbe Bitmuster ohne Kontext nicht eindeutig verständlich ist.
📝 Übung: Binärdarstellung anwenden
Eine LED-Anzeige verwendet fünf Lampen. Jede Lampe kann ein- oder ausgeschaltet sein. Die Lampen haben die Werte:
16 | 8 | 4 | 2 | 1
- Stelle die Zahl
19mit dieser Anzeige dar. - Stelle die Zahl
27dar. - Erkläre allgemein, wie du eine Dezimalzahl mit solchen Stellenwerten darstellen kannst.
- Begründe, warum dieses Prinzip gut zur technischen Arbeitsweise eines Computers passt.
Lösungsskizze
19 = 16 + 2 + 1→1001127 = 16 + 8 + 2 + 1→11011- Man prüft von links nach rechts, welche Stellenwerte benötigt werden. Verwendete Stellen erhalten eine 1, nicht verwendete eine 0.
- Die Darstellung passt zu technischen Ein-/Aus-Zuständen.
📝 Übung: Kompression bewerten
Ein Chatprogramm soll Bilder automatisch verkleinern, bevor sie verschickt werden.
- Erkläre, warum das sinnvoll sein kann.
- Unterscheide verlustfreie und verlustbehaftete Kompression.
- Beurteile, wann Qualitätsverlust akzeptabel ist und wann nicht.
- Vergleiche kurz RLE und Huffman-Codierung hinsichtlich ihrer Grundidee.
Lösungshinweis
- Kleinere Dateien benötigen weniger Speicherplatz und können schneller übertragen werden.
- Verlustfrei bedeutet: Das Original kann exakt wiederhergestellt werden. Verlustbehaftet bedeutet: Informationen gehen dauerhaft verloren.
- Qualitätsverlust kann bei Fotos oder Videos akzeptabel sein, wenn er kaum sichtbar ist. Bei Programmen, Texten oder Messdaten darf Information nicht einfach verloren gehen.
- RLE speichert Wiederholungen gleicher Zeichen kompakter. Huffman vergibt kurze Codes an häufige Zeichen und längere Codes an seltene Zeichen.
Ich kann …
Nach der Wiederholung dieses Themenbereichs solltest du Folgendes können:
- Ich kann Computational Thinking in eigenen Worten erklären.
- Ich kann die vier Grundprinzipien Zerlegung, Mustererkennung, Abstraktion und algorithmisches Denken unterscheiden.
- Ich kann ein Alltagsproblem in Teilprobleme zerlegen und als Schrittfolge beschreiben.
- Ich kann erklären, warum Menschen vernetzt denken können, Computerprogramme aber eindeutige Anweisungen benötigen.
- Ich kann beschreiben, wie Informationen digital als Bitmuster dargestellt werden.
- Ich kann erklären, warum Bitmuster erst durch Interpretation zu sinnvoller Information werden.
- Ich kann Binärzahlen in Dezimalzahlen umwandeln und einfache Dezimalzahlen binär darstellen.
- Ich kann erklären, warum Binärzahlen auf Zweierpotenzen beruhen.
- Ich kann begründen, warum Computer technisch mit binären Zuständen arbeiten.
- Ich kann typische Dateigrößen grob einschätzen.
- Ich kann verlustfreie und verlustbehaftete Kompression unterscheiden.
- Ich kann einfache Schwarz-Weiß-Bilder als Bitmuster interpretieren.
- Ich kann erklären, warum moderne Farbbilder deutlich mehr Speicherplatz benötigen als einfache Schwarz-Weiß-Grafiken.
- Ich kann die Grundidee der Lauflängencodierung erklären und beurteilen, wann sie sinnvoll ist.
- Ich kann erklären, warum eine Lauflänge wie
6×0selbst wieder binär codiert werden muss. - Ich kann aus Zeichenhäufigkeiten einen einfachen Huffman-Baum ableiten und die Bitanzahl vergleichen.
- Ich kann Chancen und Grenzen informatischer Denkweisen anhand konkreter Beispiele reflektieren.
Mini-Check
Beantworte zum Abschluss kurz:
- Was ist der Unterschied zwischen Daten und Information?
- Warum ist Abstraktion beim Problemlösen hilfreich?
- Warum kann ein Computer mit
01000001allein noch nichts „Sinnvolles“ anfangen? - Warum ist Binärdarstellung technisch robust?
- Was haben Zweierpotenzen mit Binärzahlen zu tun?
- Wann ist verlustfreie Kompression zwingend notwendig?
- Warum kann eine verlustbehaftete Kompression bei Videos sinnvoll sein?
- Warum ist
6×0bei RLE noch kein fertiger Binärcode? - Warum erhalten häufige Zeichen bei Huffman kurze Codes?
- Warum muss beim Huffman-Baum eindeutig festgelegt werden, welche Kanten
0und welche1bedeuten?
Kurzlösungen
- Daten sind gespeicherte Zeichen oder Signale; Information entsteht durch sinnvolle Interpretation.
- Abstraktion reduziert Komplexität und hebt Wesentliches hervor.
- Das Bitmuster braucht Kontext, z. B. Zeichencode, Dateiformat oder Programm.
- Zwei Zustände lassen sich technisch zuverlässig unterscheiden.
- Jede Binärstelle entspricht einer Zweierpotenz: 1, 2, 4, 8, 16, ...
- Wenn das Original exakt wiederhergestellt werden muss, z. B. bei Programmen oder Textdaten.
- Weil kleine Qualitätsverluste oft kaum auffallen, aber Speicherplatz und Bandbreite sparen.
- Weil auch die Lauflänge
6selbst wieder eindeutig binär codiert werden muss. - Weil dadurch die Gesamtzahl der benötigten Bits sinkt.
- Weil sonst unterschiedliche Personen oder Programme denselben Baum unterschiedlich lesen könnten.